Python_note
2023-10-08 16:22:20 python python
Python数据容器
数据容器入门
学习目标:
1. 数据容器是什么?
2. Python中有哪些数据容器?
- 定义:一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。
- 数据容器根据不同的特点,如
2.1. 是否支持重复元素
2.2. 是否可修改
2.3 是否有序等- 分为五类,分别是:
列标(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)
数据容器——list(列表)
列表的定义
# 基本语法
# 字面量
[元素1,元素2,元素3,元素4,元素5,...]
# 定义变量
变量名称 = [元素1,元素2,元素3,元素4,元素5,...]
# 定义空列表
变量名称 = []
变量名称 = list()
列表内的每一个数据,称之为元素
- 以[]作为标识
- 列表内每一个元素用,(逗号)隔开
案例展示
# 定义一个列表容器(数据可以不同类,这里用字符串、整型、布尔演示)
list = ["ikun",666,True]
print(list)
print(type(list))
"""
运行结果:
['ikun', 666, True]
<class 'list'>
"""
# 列表的嵌套
list = ["ikun",666,True]
list = [list,"树枝","苏珊"]
print(list)
print(type(list))
"""
运行结果:
[['ikun', 666, True], '树枝', '苏珊']
<class 'list'>
"""
列表的下标索引
题外话:索引大致方法和C语言中二维数组相似,但又有所不同
列表的下标索引是什么?
1.1. 列表的每一个元素,都有自己的编号,这个编号就称之为下标索引
1.2. 从前往后的方向,编号就是从0开始递增
1.3. 从后往前的方向,编号从-1开始递减如何通过下标索引引取出对应位置的元素呢?
列标[下标],即可取出,如下代码所示
num_text = [[1,2,3],[4,5,6],[7,8,9]]
for i in range(3):
for j in range(3):
print(f"这是num_text中第{i}行{j}列的元素:{num_text[i][j]}")
"""
运行结果:
这是num_text中第0行0列的元素:1
这是num_text中第0行1列的元素:2
这是num_text中第0行2列的元素:3
这是num_text中第1行0列的元素:4
这是num_text中第1行1列的元素:5
这是num_text中第1行2列的元素:6
这是num_text中第2行0列的元素:7
这是num_text中第2行1列的元素:8
这是num_text中第2行2列的元素:9
"""
- 下标索引的注意事项
要注意下标索引的取值范围,超出范围的无法取出元素,并且会报错(类似于指针越界)
列表的常用操作
列表的查询功能(方法)——index
查找列表的某元素的下标
功能:查找指定元素在列表的下标,如果找不到就会报错ValueError
语法:列标.index(元素)
注意:
- index就是列表对象(变量)内置的方法(函数)
- 方法就是类里面的定义的函数
- 查不了嵌套中的多个相同元素,只会返回被查到的第一个重复元素的下标
- 查嵌套中的某个元素,先要进入该元素所在层次,然后再查,如:列标[?].index(元素)
举个例子
num_text = [[1,2,3],[4,5,6],[7,8,9]]
count = 1
for i in range(3):
for j in range(3):
index = num_text[i].index(count)
print(f"这是num_text中第{i+1}行{j+1}列的元素下标:{index}")
count = count+1
"""
运行结果:
这是num_text中第1行1列的元素下标:0
这是num_text中第1行2列的元素下标:1
这是num_text中第1行3列的元素下标:2
这是num_text中第2行1列的元素下标:0
这是num_text中第2行2列的元素下标:1
这是num_text中第2行3列的元素下标:2
这是num_text中第3行1列的元素下标:0
这是num_text中第3行2列的元素下标:1
这是num_text中第3行3列的元素下标:2
"""
在上面这段代码中,通过两层循环,i循环控制行的变换,j循环控制列变换,然后通过变量count实现查找数组里面的每个数,从而通过index找出所在下标。
注意:每一行的列表角标都是从0开始,而不是继承上一行最的下标
列表的插入功能——insert
这个函数的功能就是实现在列表的的某两个元素之间插入一个新的元素
语法: 列表.insert(下标,元素),在指定的下标位置,插入指定的元素
举个例子
list = ["ikun",666,True]
list = [list,"树枝","苏珊"]
list.insert(1,'这里插入一个篮球')
print(list)
"""
运行结果:
[['ikun', 666, True], '这里插入一个篮球', '树枝', '苏珊']
"""
从上面这个例子我们可以看出,重复的变量名都能储存数据,但是调用这个变量的时候,只会调用最后一次定义的变量所储存的内容。
追加元素——append
语法: 列表的.append(元素),将指定元素,追加到列表的尾部
案例展示
list.append("这里在列表最后插入了个:篮球")
print(list)
"""
运行结果:
[['ikun', 666, True], '这里插入一个篮球', '树枝', '苏珊', '这里在列表最后插入了个:篮球']
"""
既然可以追加元素,那么是否我们也能增加列表呢?当然可以! 追加元素方式2——extend
语法: 列表.extend(其他数据容器),将其他数据容器的内容取出,依次追加到列标尾部
案例展示
list_1 = ["荔枝","苏珊","666"]
list_2 = ["香煎煎鱼","食不食油饼"]
list_1.extend(list_2)
print(list_1)
"""
运行结果:
['荔枝', '苏珊', '666', '香煎煎鱼', '食不食油饼']
"""
元素的删除——del和pop
语法1:del列表(下标)
语法2:列表.pop(下标)
del 和 pop 代码案例展示
# 利用“del 列标[下标]的方法
list = ["苏珊","666"]
del list[0]
print(f"利用“del 列标[下标]的方法,删去后列表为:{list}")
# 利用“列标.pop[下标]的方法
list = ["苏珊","666"]
list.pop(1)
print(f"利用“列标.pop[下标]的方法,删去后列表为:{list}")
# 利用pop剪切粘贴的方法
list = ["苏珊","666"]
element = list.pop(1)
print(f"利用“列标.pop[下标]的方法,删去后列表为:{list},删去后剪切粘贴为:element = {element}")
"""
运行结果:
利用“del 列标[下标]的方法,删去后列表为:['666']
利用“列标.pop[下标]的方法,删去后列表为:['苏珊']
利用“列标.pop[下标]的方法,删去后列表为:['苏珊'],删去后剪切粘贴为:element = 666
"""
注:这里不能用下面这个例子来剪切粘贴
list = ["苏珊","666"] list.pop(1) element = list.pop(1) print(f"利用“列标.pop[下标]的方法,删去后列表为:{list},删去后剪切粘贴为:{element}")剪切的时候必须要有一个变量来接受剪切的内容,无变量接受时,剪切掉的内容那部分空间就会被释放,就被永久删除了
元素的删除——remove
功能:删除某元素在列表中的第一个匹配项
语法:列表.remove(元素)
代码案例
# 元素的删除——remove
list = ["苏珊","666","苏珊"]
list.remove("苏珊")
print(f"通过“列表.remove(元素)”的方法,后列表为:{list}")
"""
运行结果:
通过“列表.remove(元素)”的方法,后列表为:['666', '苏珊']
"""
注:从上面这个案例可以看出来,remove运行原理就是遍历列表找出第一个与删除元素相同的元素,删去后结束,不会再管列标后续中重复的元素
小结
这里简单数一下del、pop和remove的区别
- 可以简单的记为一命名二方法
- del为删除命令,pop和remove为list的内置方法
- 函数和方法本质相同,但是方法是封装在一个类中,只能用于该类创建的对象调用,函数就没这个限制了
- 列表就是一个Python的内置类,pop是列表类封装的实现元素删除功能的方法(也就是list内置的函数 )
- 语法一和语法二下标为-1的时候,都会删除最后一个元素,当下标不在列表范围内时就会报错,或者说,只要超出下标都会发生越界报错
- del和remove只是单纯的删除,然而pop则是剪切粘贴
清空列表——clear
功能:顾名思义,就是把列标内容清空
语法:列表.clear()
案例展示
# 列表的清空——clear
list = ["苏珊","666"]
list.clear()
print(f"通过“列表.clear()”的方法,清空后列表为:{list}")
"""
运行结果:
通过“列表.clear()”的方法,清空后列表为:[]
"""
统计元素——count
功能:统计某元素在列表内的数量
语法:列表.count(元素)
案列展示
# 统计元素——count
list = ["苏珊","666","苏珊"]
count = list.count("苏珊")
print(f"通过“列表.count(元素)”的方法,统计出”list“中“{list[0]}”元素个数为:{count}")
print(f"{count}")
"""
运行结果:
通过“列表.count(元素)”的方法,统计出”list“中苏珊元素个数为:2
"""
注:如果是嵌套列表,那么要标明需要统计的列表下标
统计列表元素个数——len
功能:统计列表内,有多少元素,返回一个int类型,表示列表内的元素数量
语法:len(列表)
代码展示
# 统计列表元素个数——len
num_text = [[1,2,3],[4,5,6]]
num = len(num_text)
print(f"“num_text”中元素个数为:{num}")
num = len(num_text[0])
print(f"“num_text[0]”中元素个数为:{num}")
"""
运行结果:
“num_text”中元素个数为:2
“num_text[0]”中元素个数为:3
"""
注:不难发现,同count统计某元素个数一样,如果是嵌套列表,那么都是得要标明需要统计的列表下标,才能统计出需要的结果
总结
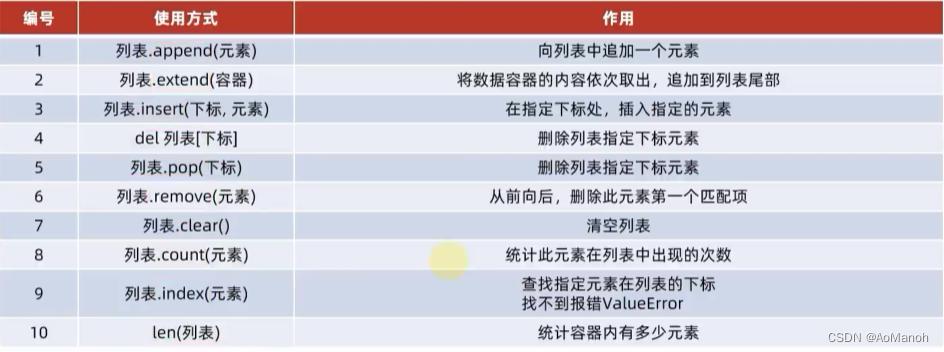
列表的特点
- 可以容纳多个元素(上限为2^63-1 - 9223372036854775807个)
- 可以容纳不同类型的元素(混装)
- 数据是有序储存的(有下标序号)
- 允许重复数据存在
- 可以修改(增加或删除元素等)
练习:常用功能练习

代码展示
# 定义列表并用变量接受它
num_list = [21, 25, 21, 23, 22, 20]
print(f"定义列表并用变量接受它:num_list = {num_list}\n")
# 追加一个数字31,到列表的尾部
num_list.append(31)
print(f"追加一个数字31,到列表的尾部:{num_list}\n")
# 追加一个新列表[29,33,30]到列表的尾部
new_list = [29,33,30]
num_list.extend(new_list)
print(f"追加一个新列表:new_list = [29,33,30],到列表num_list的尾部:{num_list}\n")
# 取出第一个元素(应是:21)
element = num_list.pop(0)
print(f"取出第一个元素num_list.pop(0)(应是:21):element = {element}\n"f"此时列表更新为:{num_list}\n")
# 取出最后一个元素(应是:30)
element = num_list.pop(8)
print(f"取出第一个元素num_list.pop(0)(应是:30):element = {element}\n"f"此时列表更新为:{num_list}\n")
# 查找元素31,在列中的下标位置
print(f"查找元素31,在列中的下标位置为:num_list.index(31) = {num_list.index(31)}")
"""
运行结果:
定义列表并用变量接受它:num_list = [21, 25, 21, 23, 22, 20]
追加一个数字31,到列表的尾部:[21, 25, 21, 23, 22, 20, 31]
追加一个新列表:new_list = [29,33,30],到列表num_list的尾部:[21, 25, 21, 23, 22, 20, 31, 29, 33, 30]
取出第一个元素num_list.pop(0)(应是:21):element = 21
此时列表更新为:[25, 21, 23, 22, 20, 31, 29, 33, 30]
取出第一个元素num_list.pop(0)(应是:30):element = 30
此时列表更新为:[25, 21, 23, 22, 20, 31, 29, 33]
查找元素31,在列中的下标位置为:num_list.index(31) = 5
"""
list(列表)的遍历
学习目标:
**1. 掌握使用while循环遍历列表元素
- 掌握使用for循环遍历列表元素**
什么叫做遍历?
将容器内的元素依次取出进行处理的行为称之为:遍历、迭代
如何遍历列表的元素呢?
- 可以使用前面学过的while循环
如何在循环中取出列表的元素呢?
- 使用列标[下标]的方式取出
循环条件怎么控制?
- 定义一个变量表示下标,从0开始
- 循环条件为:下标值 < 列表的元素数量
两种循环的语法概述
while循环:
while 循环结束条件是否满足判断: 循环主体+对循环结束条件进行处理for循环:
for 临时变量 in 数据容器: 循环变量+对临时变量进行处理
while循环演示
# while循环遍历列表元素
num_text = [[1,2,3],[4,5,6],[7,8,9]]
# 定义一个变量从0开始
count = 0
while count < len(num_text):
# 通过index获得元素下标
print(f"下标为count = {count}时,列表元素为:{num_text[count]}")
count += 1
"""
运行结果:
下标为count = 0时,列表元素为:[1, 2, 3]
下标为count = 1时,列表元素为:[4, 5, 6]
下标为count = 2时,列表元素为:[7, 8, 9]
"""
for循环演示
# for循环遍历列表元素
num_text = [[1,2,3],[4,5,6],[7,8,9]]
for i in range(3):
for j in range(3):
print(f"这是num_text中第{i}行{j}列的元素:{num_text[i][j]}")
"""
运行结果:
这是num_text中第0行0列的元素:1
这是num_text中第0行1列的元素:2
这是num_text中第0行2列的元素:3
这是num_text中第1行0列的元素:4
这是num_text中第1行1列的元素:5
这是num_text中第1行2列的元素:6
这是num_text中第2行0列的元素:7
这是num_text中第2行1列的元素:8
这是num_text中第2行2列的元素:9
"""
while循环和for循环,都是循环语句,但细节不同:
在循环控制上:
- while循环可以自定循环条件﹐并自行控制
- for循环不可以自定循环条件﹐只可以一个个从容器内取出数据
在无限循环上:
- while循环可以通过条件控制做到无限循环
- for循环理论上不可以,因为被遍历的容器容量不是无限的
在使用场景上:
- while循环适用于任何想要循环的场景 .
- for循环适用于,遍历数据容器的场景或简单的固定次数循环场景
总结
1. 什么是遍历?
- 将容器内的元素依次取出,并处理,称之为遍历操作
2. 如何遍历列表的元素?
- 可以使用while或for循环
3. for循环的语法:
for 临时变量 in 数据容器: 对临时变量进行处理4. for循环和while对比.
- for循环更简单,while更灵活
- for用于从容器内依次取出元素并处理,while用以任何需要循环的 场暑
练习案例:取出列表内的偶数

代码展示
# 定义一个列表,内容是:[1,2,3,4,5,6,7,8,9,10]
num = [1,2,3,4,5,6,7,8,9,10]
# list空数组接受偶数数组
list_while = []
list_for = []
# while循环获得数组
count = 0
while count < len(num):
if num[count] % 2 == 0:
list_while.append(num[count])
count += 1
print(f"通过while循环,从列表:num = [1,2,3,4,5,6,7,8,9,10]中取出偶数,组成新列表为{list_while}")
# for循环获得数组
for i in range(0,len(num)):
if num[i] % 2 == 0:
list_for.append(num[i])
print(f"通过for循环,从列表:num = [1,2,3,4,5,6,7,8,9,10]中取出偶数,组成新列表为{list_for}")
"""
运行结果:
通过while循环,从列表:num = [1,2,3,4,5,6,7,8,9,10]中取出偶数,组成新列表为[2, 4, 6, 8, 10]
通过for循环,从列表:num = [1,2,3,4,5,6,7,8,9,10]中取出偶数,组成新列表为[2, 4, 6, 8, 10]/
"""
数据容器:tuple(元组)
思考: 列表是可以修改的,如果想传递的信息不能被串改,列表就不再适合了
为了解决这个问题,我们就引入了元组来实现对数组信息的封装,并且封装的数据无法篡改
定义元组
元组定义:定义元组使用小括号,且使用逗号隔开各个数组,数据可以是不同的数据类型。
# 定义元组字面量 (元素, 元素, ......,元素) # 定义元组变量 变量名称 = (元素, 元素, ......,元素) # 定义空元组 变量名称 = () # 方式一 变量名称 = tuple() # 方式二
代码展示
# 定义元组
t1 = (666,"苏珊",True)
t2 = ()
t3 = tuple()
print(f"t1的类型是:{type(t1)},内容是:{t1}")
"""
运行结果:
t1的类型是:<class 'tuple'>,内容是:(666, '苏珊', True)
"""
注1: 元组只有一个数据时,这个数据后面要添加逗号,如 tuple = ("蒸虾头",),否则就不是元组类型了
注2: 由于元组的不可修改性,所以列表中的增删改查哪些功能(前文所提的list相关操作),元组只能使用 index()、count()、len(元组) 这几个
注3: 元组的下标用法同列表一样
代码展示:
# 元组的操作:index查找某元素下标
list_tuple = ["苏珊","666","苏珊"]
print(f"在元组中“list_tuple”查找“666”的下标是:{list_tuple.index('苏珊')}")
# 元组的操作:count统计某元素个数
print(f"在元组“list_tuple”中,“苏珊”的元素个数为:{list_tuple.count('苏珊')}")
# 元组的操作:len统计元组元素数量
print(f"在元组“list_tuple”中,元组元素个数共为:{len(list_tuple)}")
"""
运行结果:
在元组中“list_tuple”查找“666”的下标是:0
在元组“list_tuple”中,“苏珊”的元素个数为:2
在元组“list_tuple”中,元组元素个数共为:3
"""
# 元组的遍历
# 定义一个数组,内容是:(1,2,3)
num = (1,2,3)
# list空数组接受偶数数组
list_while = ()
list_for = ()
# while循环获得元组
count = 0
while count < len(num):
if count == 0:
print(f"通过while循环,从元组:num = (1,2,3)开始遍历,依次为:{num[count]} ",end='')
else:
print(f"{num[count]} ",end='')
count += 1
if count == len(num):
print("")
# for循环获得元组
for i in range(0,len(num)):
if i == 0:
print(f"通过for循环,从元组:num = (1,2,3)开始遍历,依次为:{num[i]} ",end='')
else:
print(f"{num[i]} ",end='')
if i == len(num):
print("\n")
"""
运行结果:
通过while循环,从元组:num = (1,2,3)开始遍历,依次为:1 2 3
通过for循环,从元组:num = (1,2,3)开始遍历,依次为:1 2 3
"""
通过上面的例子,我们可以看出元组里面的内容我们只能查看,如果你想对内容进行小小的改变,就会给你大大的报错
但是,这里我们来思考一个问题,存在于列表里的元组和存在于元组里面的列表,这种情况下又是怎么样的呢?
咱们来讨论一下吧
# 存在于列表中的元组和存在于元组中的列表修改情况讨论
tuple = (1,2,3,["荔枝",666,True])
list = ["荔枝",666,True, (1,2,3)]
# 存在于元组中的列表
print(f"这是存在于元组中的列表:{tuple}")
tuple[3][1] = 6
print(f"这是修改后的列表:{tuple}")
# 存在于列表中的元组
print(f"这是存在于列表中的元组:{list}")
list[3][0] = 0
print(f"这是修改后的元组:{list}")
"""
运行结果:
这是存在于元组中的列表:(1, 2, 3, ['荔枝', 666, True])
这是修改后的列表:(1, 2, 3, ['荔枝', 6, True])
这是存在于列表中的元组:['荔枝', 666, True, (1, 2, 3)]
Traceback (most recent call last):
File "C:\learn\上课.py", line 1544, in <module>
list[3][0] = 0
~~~~~~~^^^
TypeError: 'tuple' object does not support item assignment
"""
从上面的例子我们不难看出:
- 列表元素可以被修改,无论他在不在元组之中
- 元组元素不可被修改,无论他在不在列表之中
- 总之,对元组本身内容是无法进行修改操作的
经过上述对元组的学习,可以总结出列表有如下特点:
- 可以容纳多个数据
- 可以容纳不同类型的教据(混装)。
- 数据是有序存储的(下标索引)
- 允许重复数据存在
- 不可以修改(增加或删除元素等),但是可以修改内部list内部元素
- 支持for循环
- 多数特性和list一致,不同点在于不可修改的特性
练习案例:元组的基本操作

代码展示:
tuple = ('周杰轮', 11, ['football', 'music'])
print(f"1. 年龄所在下标位置为:{tuple.index(11)}")
print(f"2. 年龄所在下标位置为:{tuple[0]}")
tuple[2].remove('football')
print(f"3. 删除学生爱好中的football后元组为:{tuple}")
tuple[2].insert(0,"coding")
print(f"4. 增加爱好:coding到list内后元组为:{tuple}")
"""
运行结果:
1. 年龄所在下标位置为:1
2. 年龄所在下标位置为:周杰轮
3. 删除学生爱好中的football后元组为:('周杰轮', 11, ['music'])
4. 增加爱好:coding到list内后元组为:('周杰轮', 11, ['coding', 'music'])
"""
数据容器:str(字符串)
和其他容器如:列表、元组一样,字符串也可以通过下标进行访问
- 从前往后,下标从0开始
- 从后往前,下标从-1开始
#通过下标获取特定位置字符 name = "ikun" print(name[o]) #结果i print(name[-1]) #结果n
同元组一样,字符串是一个:无法修改的数据容器,所以:
- 修改指定下标的字符 (如:字符串[0] = “a”)
- 移除特定下标的字符 (如:del 字符串[0]、字符串.remove()、字符串.pop()等)
- 追加字符 (如:字符串.append())
以上操作均无法完成。如果必须要做,只能得到一个新的字符串,旧的字符串是无法修改的
对这句话,下面用几个有关字符串的函数来演示
字符串的替换——replace
语法: 字符串.replace(字符串1, 字符串2)
功能: 将字符串内的全部字符串1替换为字符串2
注意: 不是修改字符串本身,而是得到了一个新的字符串
代码展示
str = "ikun 树枝 狸猫 666"
new_str = str.replace('狸猫', '荔枝')
print(f"原字符串为:str = {str},更改后字符串为:new_str = {new_str}")
# 当然,如果你是这么搞也是可以运行处同样效果的
str = "ikun 树枝 狸猫 666"
print(f"原字符串为:str = {str},更改后字符串为:new_str = {str.replace('狸猫', '荔枝')},类型为:{type(new_str)}")
"""
运行结果:
原字符串为:str = ikun 树枝 狸猫 666,更改后字符串为:new_str = ikun 树枝 荔枝 666,类型为:<class 'str'>
"""
字符串的分割——split
语法: 字符串.split(分隔符字符)
功能: 按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中
注意: 字符串本身不变,而是得到了一个列表对象
代码展示
# 字符串的分割
str = "ikun 树枝 狸猫 666"
new_str = str.split(" ")
print(f"原字符串为:str = {str},分割后字符串为:new_str = {new_str},类型为:{type(new_str)}")
# 当然,如果你是这么搞也是可以运行处同样效果的
str = "ikun 树枝 狸猫 666"
print(f"原字符串为:str = {str},分割后字符串为:new_str = {str.split()},类型为:{type(new_str)}")
"""
运行结果:
原字符串为:str = ikun 树枝 狸猫 666,分割后字符串为:new_str = ['ikun', '树枝', '狸猫', '666'],类型为:<class 'list'>
"""
字符串的规整操作()——strip
语法: 字符串.strip() 或则 字符串.strip(字符串)
功能: 去前后空格和换行符等或者去前后指定字符串
注意:
- 传入的是“ab”,那么整个字符串中的a、b均会被移除
- 它是字符串逐个字符和参数字符进行匹配,匹配到就继续,不吻合就结束,从前往后,从后往前各一次
- 一定要记得,只是对字符串前后进行操作,中间内容一律不管!!!
代码案例
# 字符串的规整操作——strip
str = " ikun 树枝 狸猫 666 "
new_str = str.strip()
print(f"字符串str = {str},被strip去前后空格后,结果为:{new_str}")
str = "ikun 树枝 狸猫 666 狸猫"
new_str = str.strip('狸猫')
print(f"字符串str = {str},被strip('狸猫')去前括号内容后,结果为:{new_str}")
"""
运行结果:
字符串str = ikun 树枝 狸猫 666 ,被strip去前后空格后,结果为:ikun 树枝 狸猫 666
字符串str = ikun 树枝 狸猫 666 狸猫,被strip('狸猫')去前括号内容后,结果为:ikun 树枝 狸猫 666
"""
上面代码案例中
str = "ikun 树枝 狸猫 666 狸猫"这一句就是为了更清楚的理解取出前后指定字符串这句话的含义
字符串常用操作汇总
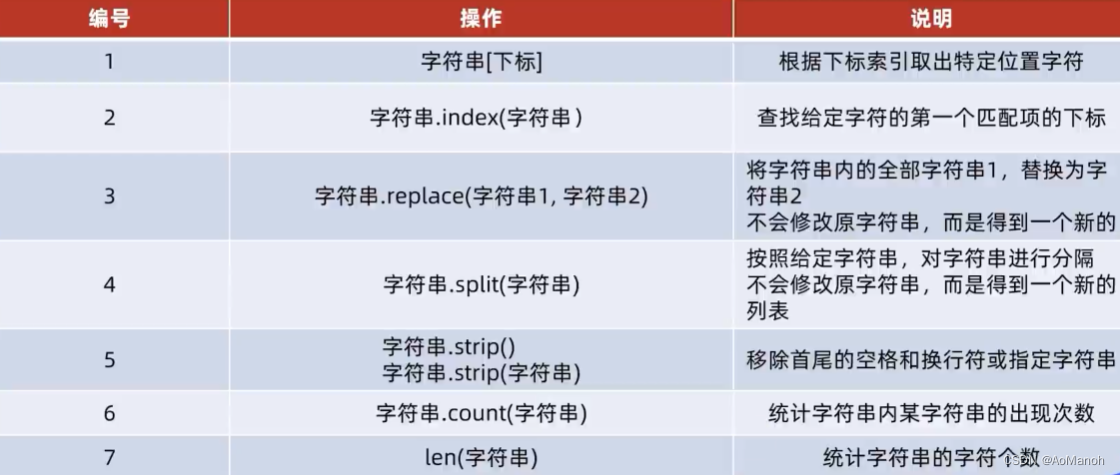
练习案例:分割字符串

代码展示
# 定义一个字符串
str = "itheima itcast boxuegu"
# 统计字符串内有多少个“it”字符
print(f"str = {str}中,有{str.count('it')}个“it”字符")
# 将字符串内的空格,全部替换成字符:“|”
print(f"str = {str}中,将字符串内的空格,全部替换成字符:“|”后为:{str.replace(' ', '|')}")
# 并按照“|”进行字符串分割,得到列表
str = "itheima itcast boxuegu"
str = str.replace(' ', '|')
print(f"str = {str}中,按照“|”分割后为:{str.split('|')}")
# print(f"str = {str.replace(' ', '|')}中,按照“|”分割后为:{str.split('|')}")
"""
运行结果:
str = itheima itcast boxuegu中,有2个“it”字符
str = itheima itcast boxuegu中,将字符串内的空格,全部替换成字符:“|”后为:itheima|itcast|boxuegu
str = itheima|itcast|boxuegu中,按照“|”分割后为:['itheima', 'itcast', 'boxuegu']
# str = itheima|itcast|boxuegu中,按照“|”分割后为:['itheima itcast boxuegu']
"""
为什么两个print输出语句不同呢?
- 因为第一个print语句中修改了str的值,而在第二个print语句中又重新修改了str的值。具体来说,你在第一行代码中用replace()方法把str中的空格替换成了|,并且把结果赋值给了str。这样,str的值就变成了 “itheima|itcast|boxuegu”。然后你在第一个print语句中用split()方法把str按照|分割成了一个列表,并且打印出来。这样,你就看到了 [“itheima”, “itcast”, “boxuegu”] 这个输出。
- 但是,在第二个print语句中,你又用replace()方法把str中的空格替换成了|,并且把结果赋值给了str。这样,str的值就变成了 “itheima||itcast||boxuegu”。注意,这里的str已经不是原来的str了,而是经过两次替换后的新字符串。然后你在第二个print语句中用split()方法把str按照|分割成了一个列表,并且打印出来。这样,你就看到了 [“itheima”, “”, “itcast”, “”, “boxuegu”] 这个输出。
- 所以,两个print语句输出不同,是因为你在每次打印之前都修改了str的值。如果你想保持str的原始值不变,你可以用一个新的变量来接收replace()方法的返回值,而不是覆盖str本身。例如:
str = “itheima itcast boxuegu” new_str = str.replace(’ ‘, ‘|’) print(f"str = {new_str}中,按照“|”分割后为:{new_str.split(’|')}")
- print(f”str = {new_str} 中,按照“|”分割后为:{new_str.split(‘|’)}”)
这样,两个print语句就会输出相同的结果了。
数据容器(序列)的切片
学习目标
**1. 什么是序列
- 掌握序列的切片操作**
什么是序列?
- 内容连续、有序,可使用下标索引的一类数据容器
- 列表、元组、字符串,均可以可以视为序列
切片
- 定义: 从一个序列中取出一个子序列
- 语法: 序列[起始下标:结束下标:步长]
步长
- 概念:表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列:
- 起始下标表示从何处开始,可以留空,留空视作从头开始
- 结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
- 步长表示,依次取元素的间隔
- 步长1表示,一个个取元素
- 步长2表示,每次跳过1个元素取
- 步长N表示,每次跳过N-1个元素取
- 步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
注意: 此操作不会影响序列本身,而是得到一个新的序列(毕竟元组、字符串不可修改)
代码展示
# 演示对序列进行切片操作
# 起始和结束不写表示从头到尾,步长为1,可以省略
# 对list进行切片
list = [0,1,2,3,4,5,6,7,8,9]
print(f"列表:list = {list}")
print(f"对list进行切片,从1开始,4结束,步长为1:list[1:4] = {list[1:4]}")
print(f"对list进行切片,从3开始,1结束,步长为-1:list[3:1:-1] = {list[3:1:-1]}")
# 对tuple进行切片
tuple = (0,1,2,3,4,5,6,7,8,9)
print(f"元组:tuple = {tuple}")
# 这里就会演示步长为1时可以省略的案例
print(f"对tuple进行切片,不写起始结尾:tuple[:] = {tuple[:]},从1开始,4结束,步长为1:tuple[1:4] = {list[1:4]}")
print(f"对tuple进行切片,不写起始结尾,步长为-2:tuple[::-2] = {tuple[::-2]},从4开始,1结束,步长为-2:tuple[4:1:-2] = {list[4:1:-2]}")
# 对str进行切片
str = "0123456789"
print(f"字符串:str = {str}")
print(f"对str进行切片,从头开始,最后结束,步长为2:list[::2] = {list[::2]}")
print(f"对str进行切片,从头开始,最后结束,步长为-1:list[::-1] = {list[::-1]}")
"""
运行结果:
列表:list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
对list进行切片,从1开始,4结束,步长为1:list[1:4] = [1, 2, 3]
对list进行切片,从3开始,1结束,步长为-1:list[3:1:-1] = [3, 2]
元组:tuple = (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
对tuple进行切片,不写起始结尾:tuple[:] = (0, 1, 2, 3, 4, 5, 6, 7, 8, 9),从1开始,4结束,步长为1:tuple[1:4] = [1, 2, 3]
对tuple进行切片,不写起始结尾,步长为-2:tuple[::-2] = (9, 7, 5, 3, 1),从4开始,1结束,步长为-2:tuple[4:1:-2] = [4, 2]
字符串:str = 0123456789
对str进行切片,从头开始,最后结束,步长为2:list[::2] = [0, 2, 4, 6, 8]
对str进行切片,从头开始,最后结束,步长为-1:list[::-1] = [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
"""
总结
1.什么是序列?
- 内容连续、有序,支持下标索引的一类数据容器
2. 哪些数据容器可以视为序列?
- 列表、元组、字符串
3. 序列如何做切片
- 语法:序列[起始:结束:步长]
- 起始可以省略,省略从头开始·结束可以省略,省略到尾结束
- 步长可以省略,省略步长为1(可以为负数,表示倒序执行)
练习案例:序列的切片实践

代码展示
str = "万过薪月,员序程马黑来,nohtyP学"
print(f"原字符串:str = {str}",f",字符串str长度为:len(str) = {len(str)}")
print(f"“黑马程序员”中,“黑”和“员”所在原字符串下标分别为:str.index('黑') = {str.index('黑')},str.index('员') = {str.index('员')}")
# 倒序字符串切片
print(f"通过倒序切片,从下标 黑 = 9 开始,下标 员 = 5结束,步伐为-1:str[9:4:-1] = {str[9:4:-1]}")
# split分隔”,"replace替换"来"为空,倒序字符串
# split作用就是将字符串内的全部字符串1替换为字符串2,replace就是替换元素内容
print(f"通过split分隔”,“,再利用replace替换“来”为空,再倒序字符串输出")
str_new = str.split(",")[1]
print(f"通过split分隔把“,”前后分隔开,在通过去下标[1]保留“员序程马黑来”,str.split(',')/str_new = {str_new}")
str_new = str.split(",")[1].replace("来", "")[::-1]
print(f"在通过replace替换“来”为空,倒序字符串输出,str.split(',')[1].replace('来', '')[::-1]/str_new = {str_new}")
"""
运行结果:
原字符串:str = 万过薪月,员序程马黑来,nohtyP学 ,字符串str长度为:len(str) = 19
“黑马程序员”中,“黑”和“员”所在原字符串下标分别为:str.index('黑') = 9,str.index('员') = 5
通过倒序切片,从下标 黑 = 9 开始,下标 员 = 5结束,步伐为-1:str[9:4:-1] = 黑马程序员
通过split分隔”,“,再利用replace替换“来”为空,再倒序字符串输出
通过split分隔把“,”前后分隔开,在通过去下标[1]保留“员序程马黑来”,str.split(',')/str_new = 员序程马黑来
在通过replace替换“来”为空,倒序字符串输出,str.split(',')[1].replace('来', '')[::-1]/str_new = 黑马程序员
"""
数据容器:set(集合)
学习目标
**1. 掌握集合的定义格式
- 掌握集合的特点
- 掌握集合的常见操作**
集合的定义
我们目前接触到了列表、元组、字符串三个数据容器了。基本满足大多数的使用场景。为何又需要学习新的集合类型呢?
首先我们先看看列标、元组、字符串的一些特性,通过特性来分析:
- 列表可修改、支持重复元素且有序
- 元组、字符串不可修改、支持重复元素且有序
那么列表、元组、字符串存在的局限是什么呢?
局限就在于:它们都支持重复元素。
- 如果场景需要对内容做去重处理,列表、元组、字符串就不方便了
- 而集合,最主要的特点就是∶不支持元素的重复(自带去重功能)、并且内容无序
集合的定义
基本语法:
>#定义集合字面量 >{元素,元素,......,元素} >#定义集合变量 >变量名称={元素,元素,......,元素} >#定义空集合 >变量名称= set()
代码案例
# 集合定义(建议不要用set作为变量名)
my_set = {"树枝","狸猫","666","基尼太美","ikun"}
print(f"集合内容是:my_set = {my_set},数据类型是:type(my_set) = {type(my_set)}")
# 定义空集合
set_empty = set()
print(f"集合内容是:set_empty = {set_empty},数据类型是:type(set_empty) = {type(set_empty)}")
# 添加新元素
my_set.add("坤哥")
print(f"my_set通过add添加新成员后:my_set/my_set.add('坤哥') = {my_set}")
print(f"my_set通过add添加重复成员后:my_set/my_set.add('基尼太美') = {my_set}")
# 移除元素
#(再次强调,remove删除元素后就为空了,如果拿变量去接受,得到的也只是个空变量,是在原有基础上进行修改,不是得到一个新内容!)
my_set.remove('坤哥')
print(f"my_set通过remove移除成员后:my_set/my_set.remove('坤哥') = {my_set}")
# 随机取出一个元素
# 注意,pop是剪切粘贴,剪切后是有返回值的,没有变量接收返回值,那么返回值就会消失!原内容中也不会存在这个元素了
print(f"随机取出一个元素为:my_set.pop() = {my_set.pop()},剪切后原集合变为:my_set = {my_set}")
# 清空集合
my_set = my_set.clear()
print(f"清空集合后为:my_set.clear() = {my_set}")
"""
运行结果:
集合内容是:my_set = {'基尼太美', '狸猫', 'ikun', '666', '树枝'},数据类型是:type(my_set) = <class 'set'>
集合内容是:set_empty = set(),数据类型是:type(set_empty) = <class 'set'>
my_set通过add添加新成员后:my_set/my_set.add('坤哥') = {'基尼太美', '狸猫', 'ikun', '666', '坤哥', '树枝'}
my_set通过add添加重复成员后:my_set/my_set.add('基尼太美') = {'基尼太美', '狸猫', 'ikun', '666', '坤哥', '树枝'}
my_set通过remove移除成员后:my_set/my_set.remove('坤哥') = {'基尼太美', '狸猫', 'ikun', '666', '树枝'}
随机取出一个元素为:my_set.pop() = 基尼太美,剪切后原集合变为:my_set = {'狸猫', 'ikun', '666', '树枝'}
清空集合后为:my_set.clear() = None
"""
集合的常用操作——修改
取出两个集合的差集
- 语法: 集合1.difference(集合2)
- 功能: 取出集合1和集合2的差集(集合1有而集合2没有的)
- 结果: 得到一个新集合,集合1和集合2不变
消除两个集合的差集
- 语法: 集合1.difference_update(集合2)
- 功能: 在集合1中消除和集合2相同的元素
- 结果: 消除后返回为空,并且集合1元素改变,集合2不变
两个集合合并
- 语法: 集合1.union(集合2)
- 功能: 将集合1和集合2组成一个新集合
- 结果: 得到新集合,集合1和集合2不变
代码案例
# 取出两个集合的差集
set1 = {1,2,3}
set2 = {1,5,6}
new_set = set1.difference(set2)
print(f"取差集后,得到的新集合为:new_set/set1.difference(set2) = {new_set},集合1结果为:set1 = {set1},集合2结果为:set2 = {set2}")
# 消除两个集合的差集,在集合1消除和集合2中相同的元素
set1 = {1,2,3}
set2 = {1,5,6}
new_set = set1.difference_update(set2)
print(f"消除差集后,得到的新集合为:set1.difference_update(set2) = {new_set},集合1结果为:set1 = {set1},集合2结果为:set2 = {set2}")
# 两个集合合并
set1 = {1,2,3}
set2 = {1,5,6}
new_set = set1.union(set2)
print(f"合并两个集合后,得到的新集合为:set1.union(set2) = {set1.union(set2)},集合1结果为:set1 = {set1},集合2结果为:set2 = {set2}")
"""
运行结果:
取差集后,得到的新集合为:new_set/set1.difference(set2) = {2, 3},集合1结果为:set1 = {1, 2, 3},集合2结果为:set2 = {1, 5, 6}
消除差集后,得到的新集合为:set1.difference_update(set2) = None,集合1结果为:set1 = {2, 3},集合2结果为:set2 = {1, 5, 6}
合并两个集合后,得到的新集合为:new_set/set1.union(set2) = {1, 2, 3, 5, 6},集合1结果为:set1 = {1, 2, 3},集合2结果为:set2 = {1, 5, 6}
"""
集合的遍历
- 集合不支持下标索引,不能使用while循环,但是for循环可以
- 因为while循环从下标0或者-1开始,但是对于集合来说,开始下标是随机的,每次遍历的结果都存在些许差异
- 此外,其实可以用while进行遍历,但是代码会稍微复杂点
- 比较有趣的是,纯数字集合的话,如果是连号数字,就是有序遍历,并且从小到大,但是一旦不是纯数字集合后,遍历结果就会改变了(集合里面的数字还是会遵循连号有序输出)
代码案例
# 连号、非纯数字集合——连号数字从小到大输出,非数字部分位置随机
set = {3,4,2,5,"树枝","ikun"}
print("集合set遍历结果为:",end='')
for i in set:
print(f"{i} ",end='')
print()
# 非连号、非纯数字集合——数字和非数字都位置随机
set = {100,95,98,"荔枝","ikun"}
print("集合set遍历结果为:",end='')
for i in set:
print(f"{i} ",end='')
print()
# 非连号、纯数字集合的遍历——数字位置随机,但是重新遍历位置不变,同第一次一致
set = {100,95,98,96,88}
print("集合set遍历结果为:",end='')
for i in set:
print(f"{i} ",end='')
print()
"""
运行结果1:
集合set遍历结果为:2 3 4 5 ikun 树枝
集合set遍历结果为:98 100 荔枝 ikun 95
集合set遍历结果为:96 98 100 88 95
运行结果2:
集合set遍历结果为:2 3 4 5 树枝 ikun
集合set遍历结果为:98 100 ikun 荔枝 95
集合set遍历结果为:96 98 100 88 95
运行结果3:
集合set遍历结果为:2 3 4 5 树枝 ikun
集合set遍历结果为:98 荔枝 100 ikun 95
集合set遍历结果为:96 98 100 88 95
"""
其余可能性请自行尝试得出结果
集合总结
集合的常用功能总结
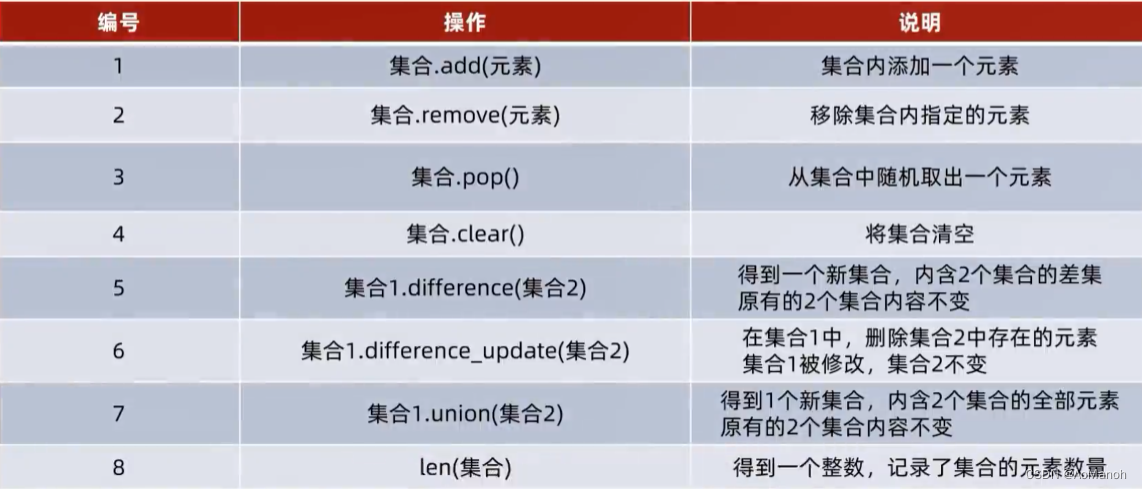
集合的特点
- 可以容纳多个数据
- 可以容纳不同类型的数据(混装)
- 数据是无序存储的(不支持持下标索引)
- 不允许重复数据存在
- 可以修改(增加或删除元素等)
- 支持for循环
练习案例:信息去重

代码案例
# 定义一个列表对象
my_list =['黑马程序员', '传智播客', '黑马程序员', '传智播客', 'itheima', 'itcast', 'itheima', 'itcast', 'best']
# 定义一个空集合
set_empty = set()
# 通过for循环遍历链表
for i in my_list:
# 在for循环中将列表的元素添加至集合
set_empty.add(i)
# 得到元素去重后的集合对象,并打印输出
print(f"得到的集合对象元素为:{set_empty}")
"""
运行结果1:
得到的集合对象元素为:{'黑马程序员', 'itheima', 'best', 'itcast', '传智播客'}
运行结果2:
得到的集合对象元素为:{'best', '传智播客', '黑马程序员', 'itcast', 'itheima'}
"""
数据容器:dict(字典、映射)
字典的定义
学习目标
1. 掌握字典的定义格式
为什么需要字典
字典的定义
- 同样使用{} ,不过储存的元素是一个个的:键值对,如下语法:
#定义字典字面量 {key: value,key : value, ......, key: value} #定义字典变量 my_dict = {key: value,key: value,..... ., key: value} #定义空字典 my_dict = {0} #空 字典定义方式1 my_dict = dict() #空字典定义方式2
代码展示
# 定义字典字面量
{"ikun":18, "坤坤":16, "树枝":666}
# 定义字典
my_dict = {"ikun":18, "坤坤":16, "树枝":666}
# 定义空字典
my_dict1 = {}
my_dict2 = dict()
print(f"字典:my_dict = {my_dict},类型为:{type(my_dict)}")
print(f"空字典1:my_dict1 = {my_dict1},类型为:{type(my_dict1)}")
print(f"空字典2:my_dict2 = {my_dict2},类型为:{type(my_dict2)}")
"""
运行结果:
字典:my_dict = {'ikun': 18, '坤坤': 16, '树枝': 666},类型为:<class 'dict'>
空字典1:my_dict1 = {},类型为:<class 'dict'>
空字典2:my_dict2 = {},类型为:<class 'dict'>
"""
我们不难发现,字典的表达和集合有点相似,集合不允许有重复,那么字典允许key重复吗?
下面我们用一个案例来展示是否允许key重复
代码展示
# 定义重复的key元素
my_dict = {"ikun":18, "树枝":666, "树枝":16}
print(f"字典:my_dict = {my_dict},类型为:{type(my_dict)}")
"""
运行结果:
字典:my_dict = {'ikun': 18, '树枝': 16},类型为:<class 'dict'>
"""
通过上面的代码案例,我们可以直观感受到key是不允许重复的,如果重复,只会出现一个,出现的究竟是谁,这个感兴趣的可以下去研究研究
从字典中基于key获取value
语法: 字典[‘key’]
代码案例
# 从字典中基于key获取value
my_dict = {"ikun":18, "坤坤":16, "树枝":666}
print(f"字典里ikun对应的value为:my_dict['ikun'] = {my_dict['ikun']}")
"""
运行结果:
字典里ikun对应的value为:my_dict['ikun'] = 18
"""
字典的嵌套
语法:
# 字典的嵌套 接受字典的变量 = {"嵌套的变量1":{key:value, key:value, ...}, "嵌套的变量2":>>{key:value, key:value, ...}, ...} # 这样看起来比较不美观,所以可以用下面这种格式 接受字典的变量 = \ { "嵌套的变量1": { key:value, key:value, ..., "嵌套的变量1中再嵌套": { key:value, key:value, ... } } "嵌套的变量2": { key:value, key:value, ... } }
注意: 如果不加 “\” ,那么请这样写:
变量 = { "嵌套内容" }
代码案例:
# 字典的嵌套
ikun_familly = \
{
# 嵌套的第一个字典——蔡徐坤
'蔡徐坤':
{
# 嵌套字典“蔡徐坤”里面的key和value
'年龄': 18,
'性别': '一个真正的man',
'最爱': '唱、跳、rap、篮球'
},
# 嵌套的第二个字典——ikun
'ikun':
{
# 嵌套字典“ikun”里面的key和value
'年龄': '666',
'性别': 'xxn',
'最爱': '坤坤'
}
}
print(f"字典嵌套里:ikun_familly = {ikun_familly}")
"""
运行结果:
字典嵌套里:ikun_familly = {'蔡徐坤': {'年龄': 18, '性别': '一个真正的man', '最爱': '唱、跳、rap、篮球'},
'ikun': {'年龄': '666', '性别': 'xxn', '最爱': '坤坤'}}
"""
注: 运行结果为了好看所以特定修改了下格式,原格式是连在一起的
从嵌套字典里获取数据
# 从嵌套字典里获取数据
print(f"ikun_familly里蔡徐坤的最爱:ikun_familly['蔡徐坤']['最爱'] = {ikun_familly['蔡徐坤']['最爱']}")
"""
运行结果:
ikun_familly里蔡徐坤的最爱:ikun_familly['蔡徐坤']['最爱'] = 唱、跳、rap、篮球
"""
字典定义的总结
1.为什么使用字典
- 字典可以提供基于Key检索Value的场景实现就像查字典一样
2.字典的定义语法
#定义字典字面量 {key: value,key: value, ......, key: value} #定义字典变量 my_dict = {key: value,key: value,......, key: value] #定义空字典 my_dict = {} #空字典定义方式1 my_dict = dict() #空字典定义方式23.字典的注意事项
- 键值对的Key和Value可以是任意类型(Key不可为列表,集合和字典,即不可为可变类型)
- 字典内Key不允许重复,重复添加等同于覆盖原有数据
- 字典不可用下标索引,而是通过Key检索Value
- 字典的嵌套,嵌套部分就是value存放的数据
字典的常用操作
学习目标:
1.掌握字典的常用操作
2.掌握字典的特点
新增元素
- 语法: 字典[key] = value
- 结果: 字典被修改,新增了元素
代码案例
ikun = \
{
'年龄': 18,
'性别': '一个真正的man',
'爱好': '唱、跳、rap、篮球'
}
# 新增元素——ikun的姓名
ikun['姓名'] = '蔡徐坤'
print(f"原字典为:ikun = {ikun}")
print(f"新增元素,ikun姓名后:ikun = {ikun}")
"""
运行结果:
原字典为:ikun = {'年龄': 18, '性别': '一个真正的man', '爱好': '唱、跳、rap、篮球', '姓名': '蔡徐坤'}
新增元素,ikun姓名后:ikun = {'年龄': 18, '性别': '一个真正的man', '爱好': '唱、跳、rap、篮球', '姓名': '蔡徐坤'}
"""
更新元素
语法: 字典[key] = value
结果: 字典被修改,元素被更新注意:
- 注1: 字典key不可以重复,所以对已存在的key执行上诉操作,就是更新value的值
- 注2: key不存在,就相当于新增;key存在,就相当于更新
代码案例
ikun = \
{
'年龄': 18,
'性别': '一个真正的man',
'爱好': '唱、跳、rap、篮球'
}
# 更新元素——ikun的年龄
print(f"原字典为:ikun = {ikun}")
ikun['年龄'] = '666'
print(f"更新年龄元素后:ikun = {ikun}")
"""
运行结果:
原字典为:ikun = {'年龄': 18, '性别': '一个真正的man', '爱好': '唱、跳、rap、篮球'}
更新年龄元素后:ikun = {'年龄': '666', '性别': '一个真正的man', '爱好': '唱、跳、rap、篮球'}
"""
删除元素
语法: 字典.pop(key)
结果: 获得指定key的value,同事字典被修改,指定key的数据被删除
注意: pop的删除本质还是剪切粘贴,所以可以用一个新的变量去接收删除的key对应的value内容。那么类比推论,像是remove、del之类的也可以用啦
代码案例
# 删除元素
ikun = \
{
'年龄': 18,
'性别': '一个真正的man',
'爱好': '唱、跳、rap、篮球'
}
# 更新元素——ikun的年龄
print(f"原字典为:ikun = {ikun}")
new_ikun = ikun.pop('年龄')
print(f"删除年龄元素为:ikun('年龄') = {new_ikun},删除后字典为:ikun = {ikun}")
"""
运行结果:
原字典为:ikun = {'年龄': 18, '性别': '一个真正的man', '爱好': '唱、跳、rap、篮球'}
删除年龄元素为:ikun('年龄') = 18,删除后字典为:ikun = {'性别': '一个真正的man', '爱好': '唱、跳、rap、篮球'}
"""
清空字典
语法: 字典.clear()
结果: 字典被修改,元素被清空
代码案例
# 清空字典
ikun = \
{
'年龄': 18,
'性别': '一个真正的man',
'爱好': '唱、跳、rap、篮球'
}
# 更新元素——ikun的年龄
print(f"原字典为:ikun = {ikun}")
ikun.clear()
print(f"清空字典后为:ikun.clear() = {ikun}")
"""
运行结果:
原字典为:ikun = {'年龄': 18, '性别': '一个真正的man', '爱好': '唱、跳、rap、篮球'}
清空字典后为:ikun.clear() = {}
"""
获取全部的key
语法: 字典.keys()
结果: 得到字典中的全部key
代码展示
# 获得全部key
ikun = \
{
'年龄': 18,
'性别': '一个真正的man',
'爱好': '唱、跳、rap、篮球'
}
print(f"ikun字典里全部的key为:ikun.keys() = {ikun.keys()}")
# 运行结果:ikun字典里全部的key为:ikun.keys() = dict_keys(['年龄', '性别', '爱好'])
遍历字典
案例展示
# 遍历字典
# 方式一:通过获取全部的key来完成遍历
for key in ikun.keys():
# 这里就是从ikun这个字典里第一个key开始遍历,直到遍历完所有的key后结束
print(f"ikun字典的key是:key = {key},",end='')
# 当前遍历的key所对应的value值进行输出
print(f"字典key对应的value = {ikun[key]}")
# 方式二:直接对字典进行for循环,每一次都是直接的得到key从而实现遍历
for key in ikun:
# 这里就是从ikun这个字典里第一个key开始遍历,直到遍历完所有的key后结束
print(f"ikun字典的key是:key = {key},",end='')
# 当前遍历的key所对应的value值进行输出
print(f"字典key对应的value = {ikun[key]}")
"""
运行结果:
ikun字典的key是:key = 年龄,字典key对应的value = 18
ikun字典的key是:key = 性别,字典key对应的value = 一个真正的man
ikun字典的key是:key = 爱好,字典key对应的value = 唱、跳、rap、篮球
"""
思考:while可以遍历字典吗?
可以,但又不完全可以,说人话就是只能间接实现
因为.key()取出来的是列表,所以我们可以通过对列表使用while循环,依次取出value从而实现对字典的遍历
字典的常用操作总结
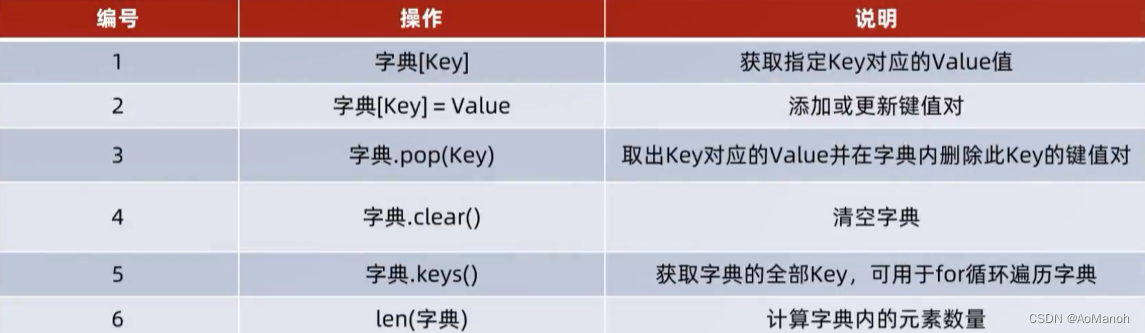
字典的特点总结
字典的特点
- 以容纳多个数据
- 可以容纳不同类型的数据
- 每一份数据是KeyValue键值对
- 可以通过Key获取到Value,Key不可重复(重复会覆盖)
- 不支持下标索引
- 可以修改(增加或删除更新元素等)
- 支持for循环,不支持while循环
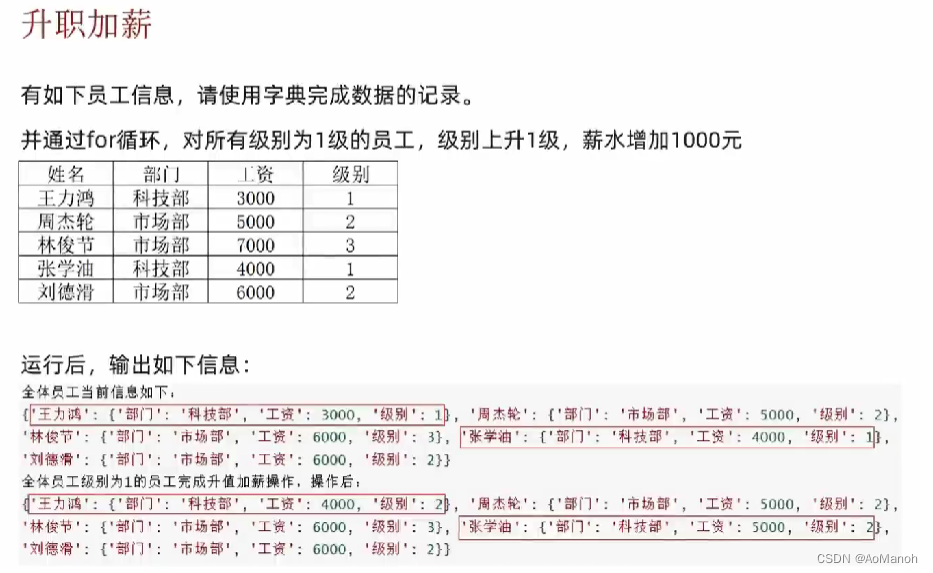
练习案例:升职加薪
# 创建员工信息
people = \
{
'王力鸿':
{
"部门": '科技部',
'工资': 3000,
'级别': 1
},
'周杰轮':
{
"部门": '市场部',
'工资': 5000,
'级别': 2
},
'林俊节':
{
"部门": '市场部',
'工资': 7000,
'级别': 3
},
'张学油':
{
"部门": '科技部',
'工资': 4000,
'级别': 1
},
'刘德滑':
{
"部门": '市场部',
'工资': 6000,
'级别': 2
}
}
# 开始输出开始时员工信息
print("全体员工当前信息如下:")
for key in people:
# print(f"{people[key]}") # 这是在打印key里面的value内容!
print(f"当前员工为:{key},员工信息为:{people[key]}")
# 更新后员工信息
print("全体员工级别为1的员工完成升职加薪操作后信息更新为:")
for key in people:
# 判断员工级别是否为1,判断成功就升职加薪
if people[key]['级别'] == 1:
people[key]['级别'] += 1
people[key]['工资'] += 1000
print(f"当前员工为:{key},员工信息为:{people[key]}")
"""
运行结果:
全体员工当前信息如下:
当前员工为:王力鸿,员工信息为:{'部门': '科技部', '工资': 3000, '级别': 1}
当前员工为:周杰轮,员工信息为:{'部门': '市场部', '工资': 5000, '级别': 2}
当前员工为:林俊节,员工信息为:{'部门': '市场部', '工资': 7000, '级别': 3}
当前员工为:张学油,员工信息为:{'部门': '科技部', '工资': 4000, '级别': 1}
当前员工为:刘德滑,员工信息为:{'部门': '市场部', '工资': 6000, '级别': 2}
全体员工级别为1的员工完成升职加薪操作后信息更新为:
当前员工为:王力鸿,员工信息为:{'部门': '科技部', '工资': 4000, '级别': 2}
当前员工为:周杰轮,员工信息为:{'部门': '市场部', '工资': 6000, '级别': 2}
当前员工为:林俊节,员工信息为:{'部门': '市场部', '工资': 8000, '级别': 3}
当前员工为:张学油,员工信息为:{'部门': '科技部', '工资': 5000, '级别': 2}
当前员工为:刘德滑,员工信息为:{'部门': '市场部', '工资': 7000, '级别': 2}
"""
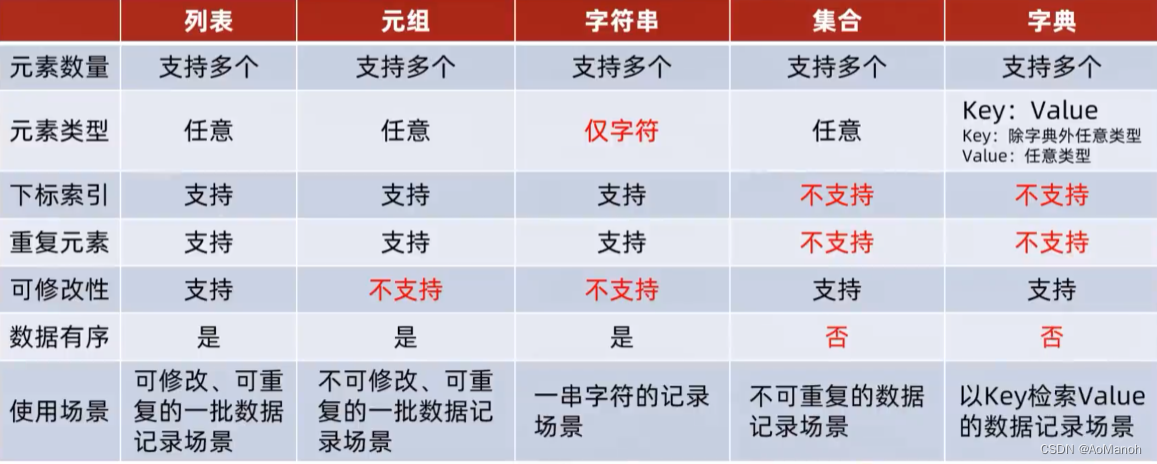
拓展:数据容器对比总结
数据容器分类
数据容器可以从以下视角进行简单的分类:·
是否支持下标索引:
- 支持:列表、元组、字符串–序列类型
- 不支持:集合、字典–非序列类型
是否支持重复元素:
- 支持:列表、元组、字符串–序列类型
- 不支持:集合、字典–非序列类型
是否可以修改:
- 支持:列表、集合、字典
- 不支持:元组、字符串
数据容器特点对比
总结
1.基于各类数据容器的特点,它们的应用场景如下:
- 列表: 一批数据,可修改、可重复的存储场景
- 元组: 一批数据,不可修改、可重复的存储场景
- 字符串: 一串字符串的存储场景
- 集合: 一批数据,去重存储场景
- 字典: 一批数据,可用Key检索Value的存储场景
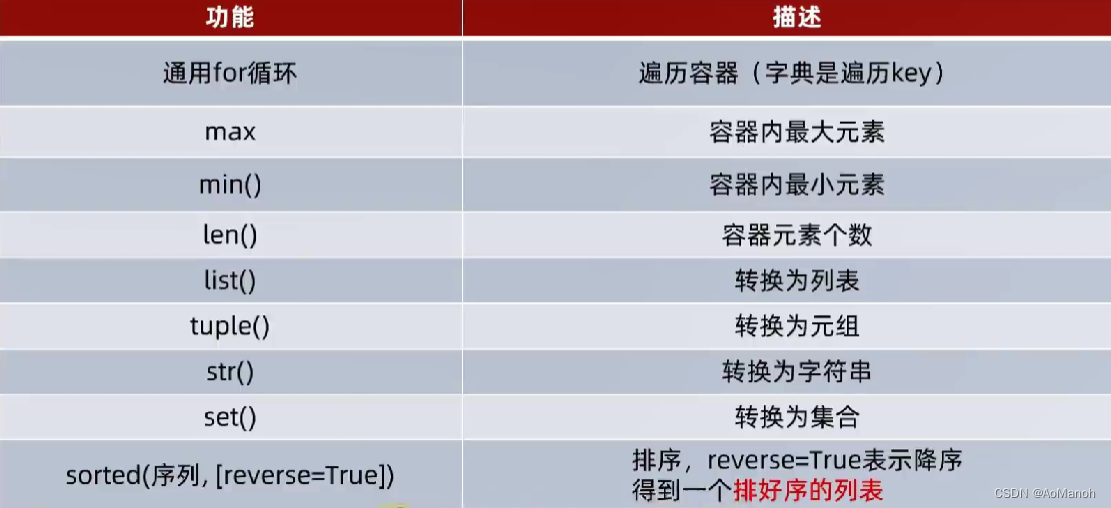
数据容器的通用操作
数据容器的通用操作——遍历
数据容器尽管各自有各自的特点,但是他们也有通用的一些操作
首先,在遍历上:
- 五类数据容器都支持for循环遍历
- 列表、元组、字符串支持while循环,集合、字典不支持(无法下标索引,只能变向实现)
尽管遍历的形式各有不同,但是他们都支持遍历操作
除了遍历这个公共性外,还有很多其他功能方法
容器查找最大最小
代码案例
# 定义列表、元组、字符串、集合和字典变量
list = [1,2,3,4,5]
tuple = (1,2,3,4,5)
str = 'abcde'
set = {1,2,3,4,5}
dict = {'key1':1, 'key2':2, 'key3':3, 'key4':4, 'key5':5}
# max最大元素
print(f"列表list最大元素是:{max(list)}")
print(f"元组tuple最大元素是:{max(tuple)}")
print(f"字符串最大元素是:{max(str)}")
print(f"集合set最大元素是:{max(set)}")
print(f"字典dict最大元素是:{max(dict)}")
# min最小元素
print(f"列表list最小元素是:{min(list)}")
print(f"元组tuple最小元素是:{min(tuple)}")
print(f"字符串最小元素是:{min(str)}")
print(f"集合set最小元素是:{min(set)}")
print(f"字典dict最小元素是:{min(dict)}")
"""
运行结果:
列表list最大元素是:5
元组tuple最大元素是:5
字符串最大元素是:e
集合set最大元素是:5
字典dict最大元素是:key5
列表list最小元素是:1
元组tuple最小元素是:1
字符串最小元素是:a
集合set最小元素是:1
字典dict最小元素是:key1
"""
思考:字符串如何实现比较大小?
详细请看拓展:字符串比较大小章节
容器的通用转换功能
- list(容器): 将给定容器转换为列表
- tuple(容器): 将给定容器转换为元组
- str(容器): 将给定容器转换为字符串
- set(容器): 将给定容器转换为集合
代码展示
my_list = [1,2,3,4,5]
my_tuple = (1,2,3,4,5)
my_str = 'abcde'
my_set = {1,2,3,4,5}
my_dict = {'key1':1, 'key2':2, 'key3':3, 'key4':4, 'key5':5}
# 类型转换:容器转列表
print(f"元组转列表的结果是:{set(my_tuple)}")
print(f"元组转列表的结果是:{list(my_tuple)}")
print(f"字符串转列表结果是:{list(my_str)}")
print(f"集合转列表的结果是:{list(my_set)}")
print(f"字典转列表的结果是:{list(my_dict)}")
"""
运行结果:
元组转列表的结果是:{1, 2, 3, 4, 5}
元组转列表的结果是:[1, 2, 3, 4, 5]
字符串转列表结果是:['a', 'b', 'c', 'd', 'e']
集合转列表的结果是:[1, 2, 3, 4, 5]
字典转列表的结果是:['key1', 'key2', 'key3', 'key4', 'key5']
"""
注意:
- 字典转列表、元组、集合会将value全部抛弃,但是转换成字符串,字典的所有内容均会保留(key和value)
容器的排序——sorted
语法: sorted(容器) 或 sorted(容器, reverse=True)
作用: 对容器内容进行正向或者逆向排序,排序的结果全部变为列表(即排序的结果会存在一个新的列表中)
代码案例
# 定义容器
my_list = [1,3,1,4,2,0]
my_tuple = (1,3,1,4,2,0)
my_str = 'acAbO'
my_set = {1,3,1,4,2,0}
my_dict = {'key1':1, 'key2':2, 'key3':3, 'key4':4, 'key5':5}
# 容器的正向排序
print(f"列表的排序为:my_list = {sorted(my_list)}")
print(f"元组的排序为:my_tuple = {sorted(my_tuple)}")
print(f"字符串的排序为:my_str = {sorted(my_str)}")
print(f"集合的排序为:my_dict = {sorted(my_dict)},my_dict.values() = {sorted(my_dict.values())} ")
# 容器的逆向排序
print(f"列表的排序为:my_list = {sorted(my_list, reverse=True)}")
print(f"元组的排序为:my_tuple = {sorted(my_tuple, reverse=True)}")
print(f"字符串的排序为:my_str = {sorted(my_str, reverse=True)}")
print(f"集合的排序为:my_dict = {sorted(my_dict, reverse=True)}, my_dict.values() = {sorted(my_dict.values())} ")
"""
运行结果:
# 容器的正向排序
列表的排序为:my_list = [0, 1, 1, 2, 3, 4]
元组的排序为:my_tuple = [0, 1, 1, 2, 3, 4]
字符串的排序为:my_str = ['A', 'O', 'a', 'b', 'c']
集合的排序为:my_dict = ['key1', 'key2', 'key3', 'key4', 'key5'],my_dict.values() = [1, 2, 3, 4, 5]
# 容器的逆向排序
列表的排序为:my_list = [4, 3, 2, 1, 1, 0]
元组的排序为:my_tuple = [4, 3, 2, 1, 1, 0]
字符串的排序为:my_str = ['c', 'b', 'a', 'O', 'A']
集合的排序为:my_dict = ['key5', 'key4', 'key3', 'key2', 'key1'], my_dict.values() = [1, 2, 3, 4, 5]
"""
容器通用功能总览
拓展:字符串比较大小
ASCIl码表:
在程序中,字符串所用的所有字符如:
- 大小写英文单词
- 数字
- 特殊符号(!、\、|、@、#、空格等)
都有其对应的ASCII码表值,详细请于网上自行查阅
每一个字符都能对应上一个:数字的码值
字符串进行比较就是基于数字的码值大小进行比较的
字符串的比较
- 字符串是按位比较,也就是一位位进行比对,只要有一位大,那么整体就大
- 按位比较的优先级大于按位数比较的优先级
- 日常应用中一般字符串只比较是否相等
- 没有值不等于空格,但空字符值等于0
代码案例
# 演示字符串大小比较
# abc比较abd
print(f"abd > abc,结果: {'abd ' > 'abc '}")
# a比较ab
print(f"ab > a,结果: { ' ab' > 'a '}")
# a比较A
print(f"a > A,结果:{'a' >'A'}")
# key1比较key2
print(f"key2 > kev1,结果:{ ' key2' > 'kev1'}")
"""
运行结果:
abd > abc,结果: True
ab > a,结果: False
a > A,结果:True
key2 > kev1,结果:False
"""
python函数进阶
函数多返回值
学习目标:
- 知道函数如何返回多个返回值
如果一个函数要有多个返回值,该如何书写代码呢?
代码案例
# 函数的多个返回值
def test_return():
return 1, 2
x, y = test_return()
print(f"x返回值为:{x},返回类型为:{type(x)}") #结果1
print(f"y返回值为:{y},返回类型为:{type(y)}") #结果2
print(f"用一个变量接收test_return()整体的话,返回值为:{test_return()},返回类型为:{type(test_return())}") #结果3
"""
运行结果:
x返回值为:1,返回类型为:<class 'int'>
y返回值为:2,返回类型为:<class 'int'>
用一个变量接收test_return()整体的话,返回值为:(1, 2),返回类型为:<class 'tuple'>
"""
注意:
- 按照返回值的顺序,写对应顺序的多个变量接收即可
- 变量之间用逗号隔开
- 支持不同类型的数据return
- 实际使用元组把这几个打了个包,即如果return1,2一个变量接收的话,数据类型就是tuple
函数多种传参方式
学习目标:
**1. 掌握位置参数
- 掌握关键字参数
- 掌握不定长参数
- 掌握缺省参数**
函数参数种类
使用方式上的不同,函数有四种常见参数的使用方式
- 位置参数
- 关键字参数
- 缺省参数
- 不定长参数
位置参数
定义: 调用函数时根据函数定义的参数位置来传递参数
def user_info(name, age, gender): print(f'您的名字是{name},年龄是{age},性别是{gender} ') user_info( 'TOM',20,'男')注意: 传递的参数和定义的参数顺序及个数必须一致
代码案例
# 演示多种传参的形式
def user(name, age, gender):
print(f"姓名是:{name},年龄是:{age},性别是:{gender}")
# 位置参数——一般默认调用形式
print(f"位置传参:user('ikun',18,'未知') = ",end='')
user('ikun',18,'未知')
# 先进行user函数的调用,然后再执行print语句,因为这个函数没有返回值,所以{}里得到的就是空内容None
print(f"位置传参:user('ikun',18,'未知') = {user('ikun',18,'未知')}")
"""
运行结果:
位置传参:user('ikun',18,'未知') = 姓名是:ikun,年龄是:18,性别是:未知
姓名是:ikun,年龄是:18,性别是:未知
位置传参:user('ikun',18,'未知') = None
"""
需要注意的是:先进行user函数的调用,然后再执行print语句,因为这个函数没有返回值,所以{}里得到的就是空内容None
关键字参数
定义: 函数调用时通过“键=值”形式传递参数
作用: 可以让函数更加清晰、更容易使用,同时也清除了参数的顺序要求def user_into(name, age, gender): print(f"您的名字是: {name},年龄是:{age},性别是:{gender}") #关键字传参 user_info(name="小明",age=20,gender="男") #可以不按照固定顺序 user_info(age=20,gender="男",name="小明") #可以和位置参数混用,位置参数必须在前,且匹配参数顺序 user_info("小明",age=20,gender="男")注意: 函数调用时,如果有位置参数时,位置参数必须在关键字参数前面,但关键字参数之间不存在先后顺序。建议别混用,不美观
代码案例
# 关键字参数
user(name='小王', age=11, gender='女')
# 可以不按照参数的定义顺序传参
user(age=10, gender='女', name='潇潇')
user('甜甜', gender='女',age=9)
"""
运行结果:
姓名是:小王,年龄是:11,性别是:女
姓名是:潇潇,年龄是:10,性别是:女
姓名是:甜甜,年龄是:9,性别是:女
"""
缺省参数
定义: 缺省参数也叫做默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值
作用: 当调用函数时没有传递参数,就会默认使用缺省参数对应的值def user_info( name,age,gender="男'): print(f'您的名字是{name},年龄是{age},性别是{gender} ' ) user_info('T0M', 20) user_info('Rose ', 18,'女')注意: 函数调用时,如果为缺省参数传值则修改默认参数值,否则使用这个默认值。此外默认参数必须写在最后面,写在前面就会报错,写后面默认参数可以连续(前面当然不行,直接报错了)
代码案例
# 缺省参数
def user(name, age, gender='男'):
print(f"姓名是:{name},年龄是:{age},性别是:{gender}")
user('ikun', 18)
user('ikun', 18, gender='女')
"""
运行结果:
姓名是:ikun,年龄是:18,性别是:男
姓名是:ikun,年龄是:18,性别是:女
# 这里给一个缺省参数在前面的错误示范案例
def user(name='ikun', age, gender='男'):
print(f"姓名是:{name},年龄是:{age},性别是:{gender}")
user('ikun', 18)
结果为:
File "C:\learn\上课.py", line 1
def user(name='ikun', age, gender='男'):
^^^
SyntaxError: non-default argument follows default argument
"""
不定长参数
定义: 不定长参数也叫可变参数.用于不确定调用的时候会传递多少个参数(不传参也可以)的场景
作用: 当调用函数时不确定参数个数时,可以使用不定长参数
不定长参数的类型:
- 位置类型
- 关键字传递
位置传递
示例:
def user(*args): print(args) # ('TOM',) user("TOM') # ('TOM', 18) user('TOM', 18)注意: 传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是位置传递
代码案例:
# 不定长——位置不定长,*号
# 不定长定义的形式参数会作为元组存在,接受不定长数量的参数传入
def user(*args):
print(f"args参数类型是:{type(args)},内容是:{args}")
user('ikun',18,'未知')
# 运行结果:args参数类型是:<class 'tuple'>,内容是:('ikun', 18, '未知')
关键字传递的不定长
示例:
def user_info(**kwargs ): print( kwargs) #{ ' name ' : 'TOM' , 'age ' : 18,'id ' : 110} user_info(name='TOM ', age=18, id=110)注意: 参数是“键=值”形式的形式的情况下,所有的“键=值”都会被kwargs接受,同时会根据“键=值”组成字典
# 不定长——关键字不定长,**号
# 数量不受限制,但是你必须按照字典那样的形式(key:value)的形式传入参数
def user(**kwargs):
print(f"kwargs参数类型是:{type(kwargs)},内容是:{kwargs}")
user(name='ikun',age=18,gender='未知')
# 运行结果:kwargs参数类型是:<class 'dict'>,内容是:{'name': 'ikun', 'age': 18, 'gender': '未知'}
总结
1. 掌握位置参数
- 根据参数位置来传递参数
2. 掌握关键字参数
- 通过“键=值”形式传递参数,可以不限参数顺序﹒可以和位置参数混用,位置参数需在前
3. 掌握缺省参数
- 不传递参数值时会使用默认的参数值-默认值的参数必须定义在最后
4. 掌握不定长参数
- 位置不定长传递以*号标记一个形式参数,以元组的形式接受参数,形式参数一般命名为args
- 关键字不定长传递以**号标记一个形式参数,以字典的形式接受参数,形式参数一般命名为kwargs
匿名函数
函数作为参数传递
学习目标:
1. 掌握函数作为参数传递
在前面的函数学习中,我们一直使用的函数,都是接收数据作为参数传入:
- 数字
- 字符串
- 字典、列表、元组等
其实,我们学习函数本身,也可以作为参数传入用另一个函数内
如下代码:

函数compute,作为参数,传入了test func函数中使用。
- test_func需要一个函数作为参数传入,这个函数需要接收2个数字进行计算,计算逻辑由这个被传入函数决定compute函数接收2个数字对其进行计算
- compute函数作为参数,传递给了test func函数使用
- 最终,在test func函数内部,由传入的compute函数,完成了对数字的计算操作
所以,这是一种,计算逻辑的传递,而非数据的传递
就像上述代码那样,不仅仅是相加,相见、相除、等任何逻辑都可以自行定义并作为函数传入
# 定义一个函数,接受另一个函数作为传入参数
def test(computer):
result = computer(1,2)
print(f"computer参数的类型是:{type(computer)},计算结果是:{result}")
# 定义一个函数,准备作为参数传入另一个函数
def computer(x,y):
return x+y
# 调用text并传入参数
test(computer)
# 运行结果:computer参数的类型是:<class 'function'>,计算结果是:3
小结:
- 函数本身是可以作为参数,传入另一个函数中进行使 用的。
- 将函数传入的作用在于∶传入计算逻辑,而非传入数 据。
LaMbda匿名函数
学习目标:
1. 掌握lambda匿名函数的语法
函数的定义中:
- def关键字,可以定义带有名称的函数
- lambda关键字,可以定义匿名函数(无名称)
有名称的函数,可以基于名称重复使用
无名称的匿名函数,只可临时使用一次
匿名函数定义语法: 1ambda传入参数:函数体(一行代码)
- lambda是关键字,表示定义匿名函数
- 传入参数表示匿名函数的形式参数,如: x, y表示接收2个形式参数
- 函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码
代码案例
# 通过def关键字,定义一个函数并传入,如下所示
def test(computer):
result = computer(1,2)
print(f"通过def关键字,computer参数的类型是:{type(computer)},计算结果是:{result}")
def computer(x,y):
return x+y
test(computer)
# 通过lambda关键字,传入一个一次性使用的拉满大匿名函数
def test(computer):
result = computer(1,2)
print(f"通过lambda关键字,computer参数的类型是:{type(computer)},计算结果是:{result}")
test(lambda x,y:x+y)
"""
运行结果:
通过def关键字,computer参数的类型是:<class 'function'>,计算结果是:3
通过lambda关键字,computer参数的类型是:<class 'function'>,计算结果是:3
"""
小结:
- 匿名函数使用lambda关键字进行定义
- 定义语法: 1ambda传入参数:函数体(一行代码)
- 注意事项:
- 匿名函数用于临时构建一个函数,只用一次的场景
- 匿名函数的定义中,函数体只能写一行代码,如果函数体要写多行 代码,不可用lambda匿名函数,应使用def定义带名函数
python文件操作
文件的编码
学习目标:
1. 掌握文件编码的概念和常见编码
文件编码
编码技术:
- 翻译的原则,记录了如何将内容翻译成二进制,以及如何将二进制翻译回可识别内容
计算机中有许多可用编码:
- UTF-8、GBK、Big5等
注意:
- 不同的编码,将内容翻译成二进制也是不同的
总结:
1. 什么是编码?
- 编码就是一种规则集合,记录了内容和二进制间进行相互转换的逻辑。 编码有许多中,我们最常用的是UTF-8编码
2.为什么需要使用编码?
- 计算机只认识0和1,所以需要将内容翻译成0和1才能保存在计算机中。 同时也需要编码,将计算机保存的0和1,反向翻译回可以识别的内容。
文件的读取
open()打开函数
在Python,使用open函数,可以打开一个己经存在的文件,或者创建一个新文件,语法如下:
open(name, mode,encoding)
- name: 是要打开的目标文件名的字符串(可以包含文件所在的具休路径)
- mode: 设置打开文件的模式(访问模式):只读、写入、追加等
- encoding: 编码格式〔推荐使用UTF-8)
示例代码:
f = open('python.txt' , 'r',encoding='UTF-8') #encoding的顺序不是第三位,所以不能用位置参数,用关键字参数直接指定注意事项:
- 此时的‘f’是‘open’函数的文件对象
- 对象是Python中一种特殊的数据类型,拥有属性和方法,可以是用对象.属性或对象.方法进行访问,后续会有更为详细的介绍
- Windows文件路径用的 \ ,但是在Python中 \ 是转义字符,所以需要用 \\ 转回去,或则直接用 /,如:
f = open("D:/测试.txt", "r", encoding='UTF-8')
代码案例
# 打开文件
# 用\\打开文件,只需要将Windows文件默认路径里的\变成\\即可
f = open("D:\\Python\\learn\\test.txt", "r", encoding='UTF-8')
# 用/打开文件,只需要将Windows文件默认路径里的\改为/即可
f = open("D:/Python/learn/test.txt", "r", encoding='UTF-8')
print(f"{type(f)}")
# 运行结果:<class '_io.TextIOWrapper'>
mode常用的三种基础访问模式
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打并一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
读取文件内容
再开始学习读取文件内容函数之前,我希望能做到:
首先心里一定要有一个很重要的文件操作指针(类似编译器里的光标)的当前位置的概念,然后所有的读取或则写入操作都是基于这个指针当前位置开始
read()方法
语法: 文件对.read(num)
注意:
- num表示要从文件中读取的数据长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据
- 在UTF-8编码中,一个汉字或者汉字标点占3个字节,一个英文或则英文标点占1个字节(但是在实际运行Python中10汉字或汉字标点就为10字节输出内容,很怪)
代码案例
# 文件的读取——read()
print(f"读取10字节test.txt文件的结果为:{f.read(10)}")
print(f"读取整个test.txt文件的结果为:{f.read()}")
"""
运行结果:
读取10字节test.txt文件的结果为:这是一个文本,文本内
读取整个test.txt文件的结果为:容为:ikun
"""
- 通过这个案例我们可以清楚,在用read读取文件时,下一个read会在上一个read读取文件的结尾处接着继续读取文件。
- 这也正是我开头希望大家心里能清楚的一个光标的概念,如果非要解释,那我只能说:
- 同一个文件对象,操作系统里,文件系统指针会记录当前文件的读取位置,下次读取时继承。所以当第一次读完后,再读一次结果就为空了
print(f"第一次读取整个test.txt文件的结果为:{f.read()}") print(f"第二次读取整个test.txt文件的结果为:{f.read()}") """ 运行结果: 第一次读取整个test.txt文件的结果为:这是一个文本,文本内容为:ikun 第二次读取整个test.txt文件的结果为: """
readlines()方法
readlines可以按照行的方式,把整个文件中的内容进行一次性读取,并且返回一个列表 ,其中每一行的数据为一个元素,如下所示
f = open('test.txt') content = f.readlines() # 读取文件的全部行,封装到列表中进行输出(这里{}内容也可以用content) print(f"f.readlines()对象类型为:{type(f.readlines())},内容为{f.readlines()}")此时就会把文件读取的内容通过prin语句输出了
但是需要注意的是:
- readlines是读取内容为list类型,而还有个很像的readline则是读取内容为str型(后面会讲),注意区分
- 此外还要记住,文件打开后,不管使用read还是readlines,读取文件都回从上一次读取结束位置开始,如果你用read()读取完文件后再用readlines,也会读不出东西来,如:
# 文件的读取——read() print(f"读取整个test.txt文件的结果为:{f.read()}") # 文件的读取——readlines() # 读取文件的全部行,封装到列表中 print(f"f.readlines()对象类型为:{type(f.readlines())},内容为{f.readlines()}") """ 运行结果: 读取整个test.txt文件的结果为:这是一个文本,文本内容为:>ikun f.readlines()对象类型为:<class 'list'>,内容为[] """
- 当然,如果你想要重新读一下文件内容,只需要再利用open()函数打开文件就行。此外,readlines打开的文件时建议一定拿新变量接收,如下所示:
# 案例1: print(f"f.readlines()对象类型为:{type(f.readlines())},内容为:{f.readlines()}") # 案例2: content = f.readlines() print(f"f.readlines()对象类型为:{type(f.readlines())},内容为:{content}") """ 运行结果: 读取整个test.txt文件的结果为:这是一个文本,文本内容为:ikun f.readlines()对象类型为:<class 'list'>,内容为:[] f.readlines()对象类型为:<class 'list'>,内容为:这是第一个文本,文本内容为:ikun """
思考: 如果我将文件进行关闭后重新打开,两者结果还会有差异吗?
readline()方法
readline也是读取文件,但是这个函数很特殊,它只读取一行文件,并且读取的类型为字符串类型
代码案例
# 文件的读取——readline()
# 读取文件的全部行,封装到列表中
f = open("D:/Python/learn/test.txt", "r", encoding='UTF-8')
content1 = f.readline()
content2 = f.readline()
print(f"f.readline()对象类型为:{type(f.readline())},内容为{content1}")
print(f"f.readline()对象类型为:{type(f.readline())},内容为{content2}")
"""
运行结果:
f.readline()对象类型为:<class 'str'>,内容为这是第一个文本
f.readline()对象类型为:<class 'str'>,内容为这是第二个文本
"""
for循环读取文件行
这里介绍一个最简单的读取案例
# for循环读取文件行
f = open("D:/Python/learn/test.txt", "r", encoding='UTF-8')
for i in f:
print(f"开始通过for循环读取文件,对象类型为:{type(i)}内容为:{i}")
"""
运行结果:
开始通过for循环读取文件,对象类型为:<class 'str'>内容为:这是第一个文本
开始通过for循环读取文件,对象类型为:<class 'str'>内容为:这是第二个文本
"""
可以看出,如果通过for循环读取文件,其实就是readline读取文件的简便化,不需要手动创建变量一一接收每一行文件的内容,大大简化代码量
文件关闭操作
第一种:
- 语法: 接收文件的变量.clsoe()
代码案例:
# 读入文件 f = open("D:/Python/learn/test.txt", "r", encoding='UTF-8') #关闭文件 f.close()注意:
- 如果通过是通过open打开文件,一定要记得close关闭文件解除文件占用,不然的话,后续对文件操作就会出错啦
第二种:
- 语法: with open() as 接受文件的变量:
代码案例:
with open("D:/Python/learn/test.txt", "r", encoding='UTF-8') as f: for i in f: print(f"开始通过for循环读取文件,对象类型为:{type(i)}内容为:{i}") """ 运行结果: 开始通过for循环读取文件,对象类型为:<class 'str'>内容为:这是第一个文本 开始通过for循环读取文件,对象类型为:<class 'str'>内容为:这是第二个文本 """注意:
- with open也叫做上下文管理器,通过with open语法读入文件,在语句介绍后文件就会自动关闭啦
总结
读取文件操作汇总
| 操作 | 功能 |
|---|---|
| 文件对象 = open(file, mode, encoding) | 打开文件获得文件对象 |
| 文件对象.read(num) | 读取指定长度字节,不指定num则读取文件全部 |
| 文件对象.readline() | 只读取一行文件内容,返回类型为字符串 |
| 文件对象.readlines() | 读取全部行,返回类型为列表 |
| for line in 文件对象 | for循环文件行,一次循环只能获得一行文件的数据 |
| 文件对象,close() | 关闭文件对象 |
| with open() as 文件对象 | 通过with open语法打开文件,语句结束后自动关闭文件 |
本章汇总
1.操作文件需要通过open函数打开文件得到文件对象
2.文件对象有如下读取方法:
- read()
- readline()
- readlines()
- for line in文件对象
3.文件读取完成后,要使用文件对象.close()方法关闭文件对象,否则文件会被一直占用
课后练习:单词计数

代码案例:
# 方法一:利用open()打开,close()关闭,for遍历文件查找
f = open("D:/Python/learn/test.txt", "r", encoding="UTF-8")
# 定义一个计数变量,用于累加每一行中"itheima"出现的次数
count = 0
# 开始遍历每一行文件的内容,统计“itheima”出现的次数
for line in f:
# line.count的返回值就是每一句文件里出现的"itheima"次数
count += line.count("itheima")
print(f"“itheima”出现的次数为:{count}")
# 关闭文件
f.close()
# 方法二:利用with open打开文件,read()读取全部文件一次性查找
with open("D:/Python/learn/test.txt", "r", encoding="UTF-8") as f:
print(f"“itheima”出现的次数为:{f.read().count('itheima')}")
"""
运行结果:
“itheima”出现的次数为:6
"""
从上面这个例子我们不难发现,方法二真的很简便!
文件的写入
让我们先来看一个代码演示来感受一下怎么写入文件
案例演示:
# 1. 打开文件——以“写/w”的形式打开一个叫“test。txt” 的文件
f = open ('test,txt','w')
# 2. 文件写入——写入新的内容到文件里
f.write('树枝666')
# 3. 内容刷新——将写入存放在write缓冲区的内容写入文件
f.flush()
注意:
- 直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
- 当调用flush的时候,内容会真正写入文件
- 这样做是避兔频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
写入案例:
# 以写的方式打开文件
f = open('D:/Python/learn/test.txt', 'w', encoding='UTF-8')
# write写入——此时内容写入了内存,但是还未写入磁盘
f.write('这是通过f.write()写入的新内容')
# flush刷新——将内存中缓冲的内容写入硬盘的文件中
f.flush()
# 写入后的文件内容读取
f = open("D:/Python/learn/test.txt", "r", encoding='UTF-8')
content = f.readlines()
print(f"通过f.write和f.flush的方式写入新内容后为:{content}")
# 关闭文件——close内置了flush方法,所以不通过f.flush()也可以实现对文件内容的更新
f.close()
# 写入后的文件内容读取
f = open("D:/Python/learn/test.txt", "r", encoding='UTF-8')
content = f.readlines()
print(f"通过f.write和f.close写入新内容后为:{content}")
"""
运行结果:
通过f.write和f.flush的方式写入新内容后为:['这是通过f.write()写入的新内容']
通过f.write和f.close写入新内容后为:['这是通过f.write()写入的新内容']
"""
注意:
- 通过write写入文件,会对原有文件内容进行覆盖
- close内置了flush方法,所以不用更新文件内容也可以将缓冲内容写入文件
- 然而很奇怪,如果你不通过flush更新和close关闭文件,事实上写入的缓冲区内容也会覆盖源文件内容,很怪,可能是新版本Python更新后更改了吧
总结
1.写入文件使用open函数的”w”模式进行写入
2.写入的方法有:
- wirte(),写入内容
- flush(),刷新内容到硬盘中
3.注意事项:
- w模式,文件不存在,会创建新文件
- w模式,文件存在,会清空原有内容
- close()方法,带有flush()方法的功能
文件的追加
让我们先来看一个代码演示来感受一下怎么写入文件
案例演示:
# 1.打开文件,通过“a”模式打开即可
f = open('test.txt','a',encoding='UTF-8')
# 2.文件写入
f.write('这是一段新插入的内容')
# 3.内容刷新
f.flush()
注意:
- 文件不存在是会先创建文件
- 文件存在会在原内容最后,追加写入文件 ,而不是像“w”写入文件一下覆盖源文件
- 想要换行输入,就可以在追加前加入 \n 实现
- 每一次运行会使文件内容重复增加,“w” 写法则不会
代码案例
# 以追加的方式打开文件
f = open('D:/Python/learn/test.txt', 'a', encoding='UTF-8')
# write写入——此时内容写入了内存,但是还未写入磁盘
f.write('\n这是通过“a”追加的新内容')
# flush刷新——将内存中缓冲的内容写入硬盘的文件中
f.flush()
# 写入后的文件内容读取
f = open("D:/Python/learn/test.txt", "r", encoding='UTF-8')
content = f.readlines()
print(f"通过f.write和f.flush的方式写入新内容后为:{content}")
# 以追加的方式打开文件
f = open('D:/Python/learn/test.txt', 'a', encoding='UTF-8')
# write写入——此时内容写入了内存,但是还未写入磁盘
f.write('\n这是通过“a”追加的新内容')
# 关闭文件——close内置了flush方法,所以不通过f.flush()也可以实现对文件内容的更新
f.close()
# 写入后的文件内容读取
f = open("D:/Python/learn/test.txt", "r", encoding='UTF-8')
content = f.readlines()
print(f"通过f.write和f.close写入新内容后为:{content}")
"""
运行结果:
通过f.write和f.flush的方式写入新内容后为:['这是通过f.write()写入的新内容\n', '这是通过“a”追加的新内容']
通过f.write和f.close写入新内容后为:['这是通过f.write()写入的新内容\n', '这是通过“a”追加的新内容']
"""
两种方式均可以在文件中实现以下格式
这是通过f.write()写入的新内容
这是通过“a”追加的新内容
总结
1.追加写入文件使用open函数的”a模式进行写入
2 追加写入的方法有(和w模式一致)︰
- wirte(),写入内容
- flush(),刷新内容到硬盘中
3.注意事项:
- a模式,文件不存在,会创建新文件
- a模式,文件存在,会在原有内容后面继续写入
- 可以使用”\n”来写出换行符
文件操作综合案例
学习目标:
1. 完成文件备份案例
需求: 有一份账单文件,记录了消费收入的具体记录,内容如下:
name, date,money,type, remarks
周杰轮,2022-01-01,100000,消费,正式
周杰轮,2022-01-02,300000,收入,正式
周杰轮,2022-01-03,100000,消费,测试
林俊节,2022-01-01,100000,收入,正式
林俊节,2022-01-02,100000,消费,测试
林俊节,2022-01-03,100000,消费,正式
林俊节,2022-01-04,100000,消费,测试
林俊节,2022-01-05,500000,收入,正式
张学油,2022-01-01,100000,消费,正式
张学油,2022-01-02,500000,收入,正式
张学油,2022-01-03,900000,收入,测试
王力鸿,2022-01-01,500000,消费,正式
王力鸿,2022-01-02,300000,消费,测试
王力鸿,2022-01-03,950000,收入,正式
刘德滑,2022-01-01,300000,消费,测试
刘德滑,2022-01-02,100000,消费,正式
刘德滑,2022-01-03,300000,消费,正式
ikun们可以将内容复制并保存为 bill.txt文件
我们现在要做的就是:
- 读取文件
- 将文件写出到bill.txt.bak文件作为备份
- 同时,将文件内标记为测试的数据行丢弃
实现思路:
- open和r模式打开一个文件对象,并读取文件
- open和w模式打开另一个文件对象,用于文件写出
- for循环内容,判断是否是测试不是测试就write写出,是测试就continue跳过
- 将2个文件对象均close()
代码案例
# 方法一
# 以读的方式打开文件进行备份
with open("D:/Python/learn/bill.txt", "r", encoding="UTF-8") as f_r:
# 以追加的方式创建一个新文件
f_a = open("D:/Python/learn/bill.txt.bak", "a", encoding="UTF-8")
# 读取源文件中的每一行内容
for line in f_r:
# 判断每一行变量"line"的内容是否为测试数据
# 如果这一行内容里有“测试”,那么count就会+1,通过判断是否为1进行每行内容的写入
if line.count('测试') != 1:
f_a.write(line)
# 读取整个bill.bak.txt文件内容,然后输出展示一下
#(这里留个伏笔,记笔记!)
# 运行结果
with open("D:/Python/learn/bill.txt.bak", "r", encoding="UTF-8") as f:
content = f.readlines()
print(f"bill.txt.bak内容为:{content}")
# 方法二
# 以读的方式打开文件进行备份
f_r = open("D:/Python/learn/bill.txt", "r", encoding="UTF-8")
# 以追加的方式创建一个新文件
f_a = open("D:/Python/learn/bill.txt.bak", "a", encoding="UTF-8")
# 读取源文件中的每一行内容
for line in f_r:
# 先将每一行文件中的换行符\n删除——strip可以将每一行内容开头结尾的空格换行符删去
line = line.strip()
# 通过字符串函数split,按照逗号(,)将每一行内容进行分割,通过下标判断内容,将满足的内容写出
if line.split(",")[4] == "测试":
continue
# 由于对内容进行了strip操作删去了\n,所以要手动写出换行符
f_a.write(line)
f_a.write('\n')
f_r.close()
f_a.close()
# 运行结果
with open("D:/Python/learn/bill.txt.bak", "r", encoding="UTF-8") as f:
content = f.readlines()
print(f"bill.txt.bak内容为:{content}")
"""
运行结果:(这里为手动换行结果,实际Python运行结果是一长条)
方法一:
bill.txt.bak内容为:[]
方法二:
bill.txt.bak内容为:[
'周杰轮,2022-01-01,100000,消费,正式\n',
'周杰轮,2022-01-02,300000,收入,正式\n',
'林俊节,2022-01-01,100000,收入,正式\n',
'林俊节,2022-01-03,100000,消费,正式\n',
'林俊节,2022-01-05,500000,收入,正式\n',
'张学油,2022-01-01,100000,消费,正式\n',
'张学油,2022-01-02,500000,收入,正式\n',
'王力鸿,2022-01-01,500000,消费,正式\n',
'王力鸿,2022-01-03,950000,收入,正式\n',
'刘德滑,2022-01-02,100000,消费,正式\n',
'刘德滑,2022-01-03,300000,消费,正式']
"""
通过结果,我们不难发现,方法一是无法将内容进行输出的。但是,如果我们打开文件,则会发现文件里已经写入了内容。此时,我们单独open打开这个文件,会正常输出内容,并且如果我们用 “w” 写法,由于该写法会覆盖原本内容,那么方法一就会一直无内容输出。方法二则是无影响。
为什么呢?
现在开始回收伏笔
- 无论是w方法还是a方法,都是先将内容输入到缓冲区内(文件的写入章节开头注意有讲),然后才是通过flush方法将缓冲区内容写入硬盘的文件内!
- 方法一之所以不成功,是因为在结尾处未关闭文件将缓冲区内容写入硬盘文件内,这才导致了有文件内容但是却无法第一时间输出
- 方法二能在运行中输出也是因为如此
此外,个人猜测,编译器运行的时候会将缓冲区内容写入硬盘,但是输出的结果是在缓冲区的内容(bushi
额外补充之文件的删除
如果我们想要删除某个特定的文件,或者是想要避免再创建文件时重名,我们就可以通过下面的方式对文件存在进行判断,然后选择是否删除
首先我们先要导入一个python的内置模块——os模块
这个模块提供了一些操作文件和目录的函数,其中os.path.exists()可以判断文件是否存在,os.remove()或则os.unlink()则可以删除文件,两个删除文件函数的区别是前者是更通用的名称,后者是Unix系统中的名称
代码案例
# 首先先导入python的os模块
import os
# 查看文件路径
path = "xxx.txt" # 文件路径
# 开始判断
if os.path.exists(path): # 如果文件存在
os.remove(path) # 删除文件
# 或者用os.unlink(path)删除文件
else: # 如果文件存在
pass # 不做任何操作/或则你可以创建文件
Python异常、模块与包
了解异常和捕获异常
学习目标:
1. 了解异常的概念
- 知道为什么要捕获异常
- 掌握捕获异常的的语法格式
了解异常
什么是异常?
当检测到一个错误时,Python解释器就无法继续执行;了,反而出现了一些错误的提示,这就是所谓的“异常”,也就是我们常说的bug
bug又是什么?
bug就是异常的意思,因为历史上,第一个计算机失灵案例是由一只小虫子造成的,所以就用小虫子 “bug” 来代表软件出错的现象,并延续至今。
为什么要捕获异常
- 世界上没有完美的程序,任何程序在运行的过程中,都有可能出现:异常,也就是出现bug导致程序无法完美运行下去。
- 我们要做的,不是力求程序完美运行, 而是在力所能及的范围内,对可能出现的bug,进行提前准备、提前处理。
- 这种行为我们称之为:异常处理(捕获异常)
当我们的程序遇到了BUG,那么接下来有两种情况:
- 整个程序因为一个BUG停止运行
- 对BG进行提醒,整个程序继续运行
显然在之前的学习中,我们所有的程序遇到BUG就会出现1的这种情况,也就是整个程序直接奔溃
但是在真实工作中,我们肯定不能因为一个小的BUG就让整个程序全部奔溃,也就是我们希望的是达到2的这种情况——那这里我们就需要使用到捕获异常
捕获异常的作用在于:
提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段进行处理
捕获常规异常
基本语法:
try:
可能错误的代码
except:
如果出现异常执行的代码
要理解,总会有些不可抗拒因素导致撰写的文案丢失,比如说电脑莫名的重启,比如浏览器莫名的崩溃关闭
丢失内容主要是异常单元、自定义模块单元、安装第三方包单元、一直到类和对象
面向对象
成员方法
类和对象
学习目标
**1. 掌握使用类描述现实世界事物的思想
- 掌握类和对象的关系
- 理解什么是面向对象**
显示世界的事物也有属性和行为,类也有属性和行为
实用程序中的类,则可以完美的描述现实世界的事物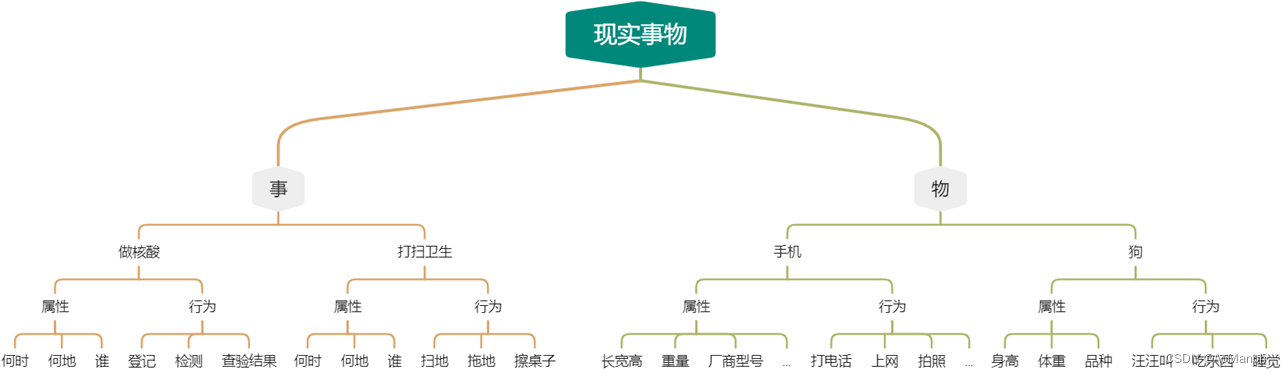
类和对象
前面的语法中,我们要创建对象后,才能使用类对象名 = 类名称(),思考一下,这为什么呢?
类是一种程序内的“设计图纸”,基于图纸生产实体(也就是对象),才能正常工作,这种讨论也被称之为:面向对象编程
构造方法
学习目标:
1. 掌握使用构造方法向成员变量赋值
属性(成员变量)的赋值
在前面的学习中,我们可以通过下面这种方法来为对象的属性进行赋值
class Student:
name = None # 学生姓名
age = None # 学生年龄
tel = None # 电话号码
stu_1 = Student()
stu_1.name = "菜虚鲲"
stu_1.age = 6
stu_1.tel = '11451466686'
stu_2 = Student()
stu_2.name = "菜虚鲲plus"
stu_2.age = 666
stu_2.tel = '114514999869'
但是吧,如果人多起来,是不是就略显繁琐了?那么有没有更高效的方式能一步搞定呢?
前面我们学函数(方法)的时候,不是可以通过传参对属性进行赋值吗?那现在对成员变量是否也可以呢?
当然,我们可以使用构造法方法: init ()
构造方法
在Python中有个方法叫做构造方法: init ()
可以实现:
- 在创建类对象(构造类)的时候,会自动执行
- 在创建类对象(构造类)的时候,将传入参数自动传递给 init 方法使用
class Student:
# name = None # 学生姓名
# age = None # 学生年龄
# tel = None # 电话号码
def __init__(self, name, age, tel):
self.name = name
self.age = age
self.tel = tel
print("我在student类里创建了一个对象")
stu = Student("菜虚鲲", 6, '11451466686')
总结
练习:学生信息录入

代码案例
# 学生信息录入
# 第一版,会覆盖上面一人的身份信息
try:
# 创建一个类来收集学生信息
class Student:
def __init__(self, name, age, address):
self.name = name
self.age = age
self.address = address
# 身份信息的录入
for student_num in range(1, 11):
print(f"当前录入第{student_num}位学生信息,总共需录入10位学生信息")
stu = Student(input("请输入学生姓名:"), input("请输入学生年龄:"), input("请输入学生地址:"))
print(f"学生{student_num},信息录入完成,信息为:【{stu.name}, {stu.age}, {stu.address}】")
except Exception as e:
print("something wrong happened")
# 第二版,将每一个人的信息依次保存
try:
# 创建一个文件,以追加的方式写入每一次导入的学生信息
with open("D:/Python/learn/student_inf.txt", 'a', encoding='UTF-8') as f:
class Student:
def __init__(self, name, age, address):
self.name = name
self.age = age
self.address = address
for student_num in range(1, 4):
print(f"当前录入第{student_num}位学生信息,总共需录入3位学生信息")
stu = Student(input("请输入学生姓名:"), input("请输入学生年龄:"), input("请输入学生地址:"))
print(f"学生{student_num},信息录入完成,信息为:【{stu.name}, {stu.age}, {stu.address}】")
# 将每一个录入的身份信息写入到student_inf文件里
f.write(stu.name + '\t' + stu.age + '\t' + '\t' + stu.address + '\n')
except Exception as e:
print("something wrong happened")
讲解一下思路
首先,创建一个类来收集学生信息没啥可说的,重点讲解一下如何将内容传入成员对象吧
我们想要从客户端哪里接受内容,那么就会用到input,前面的学习中我们可以知道,input里面输入一些文本内容可以当做print来用,并且,在用input的时候我们会创建一个新的变量用来接收客户端哪里用input输入的内容,既然这样,那我们稍加思索是不是就可以直接在Student()括号内进行传参了呢?很显然是可以的
文件内容没啥可多说的,最主要的就是写入文件时会用到之前学到的内容的拼接 +,以及格式的工整 \n
这里提一句,为什么不通过
print(student)或者print(str(student))将用户输入的信息输出而是选择稍显麻烦的{stu.name}, {stu.age}, {stu.address}呢?别着急,下节自有解释
其他内置方法
学习目标:
1. 掌握几种常用的类内置放哪发
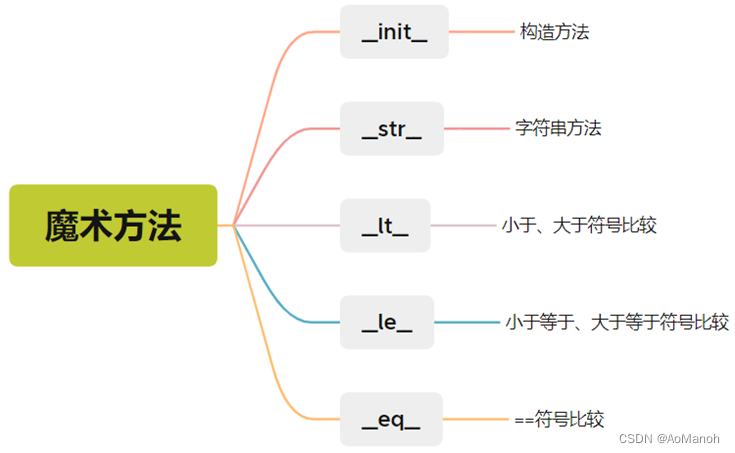
魔术方法
- 上文中学习的 init 构造方法,是Python内置的方法之一
- 对于这些内置的类方法,各自有各自特殊的功能,这些内置方法我们称之为:魔术方法
对于魔术方法,在Python中基本上前面两个下划线,后面两个下划线的就是
str 字符串方法
首先我们先看一个案例
代码案例
class Student:
def __init__(self, name, age, address):
self.name = name
self.age = age
self.address = address
stu = Student("菜虚鲲", 6, '11451466686')
print(stu)
print(str(stu))
'''
运行结果:
<__main__.Student object at 0x00000239A5A269D0>
Traceback (most recent call last):
File "D:\Python\learn\上课.py", line 2497, in <module>
print(str(stu))
^^^^^^^^
TypeError: 'str' object is not callable
'''
当这类对像需要被转换为字符串时,会输出内存地址
当然我们肯定是要内容而不是地址(况且第二个字符串转化还有问题)而 str 方法就是通过控制类转换字符串的行为来解决这个问题滴
代码案例
# __str__方法
class Student:
def __init__(self, name, age, address):
self.name = name
self.age = age
self.address = address
# 进行一个字符串的转化
def __str__(self):
return f"Student类对象,name = {self.name}, age = {self.age}, address = {self.address}"
stu = Student("菜虚鲲", 6, '蔡徐村')
print(stu)
print(str(stu))
"""
运行结果:
Student类对象,name = 菜虚鲲, age = 6, address = 蔡徐村
Traceback (most recent call last):
File "D:\Python\learn\上课.py", line 2510, in <module>
print(str(stu))
^^^^^^^^
TypeError: 'str' object is not callable
"""
lt 小于符号比较方法
直接上代码案例吧
代码案例
# __lt__小于符号比较方法
class Student:
def __init__(self, name, age, address):
self.name = name
self.age = age
self.address = address
def __lt__(self, other):
return self.age < other.age
stu_1 = Student("菜虚鲲", 6, '蔡徐村')
stu_2 = Student("菜虚鲲plus", 666, '蔡徐村')
print(stu_1.age < stu_2.age)
print(stu_1.age > stu_2.age)
print(stu_1.age <= stu_2.age)
print(stu_1.age >= stu_2.age)
print(stu_1.age == stu_2.age)
"""
运行结果:
True
False
True
False
False
"""
等等,为什么可以比较小于等于和大于等于???为什么是否相等也可以比较???那我要是不写 lt 还能比较吗?
当然可以!最新版的是支持直接比较的,就不需要通过 lt 方法,后面的 小于等于或大于等于比较 le 方法,以及 比较是否相等 eq 方法也默认支持啦
总结
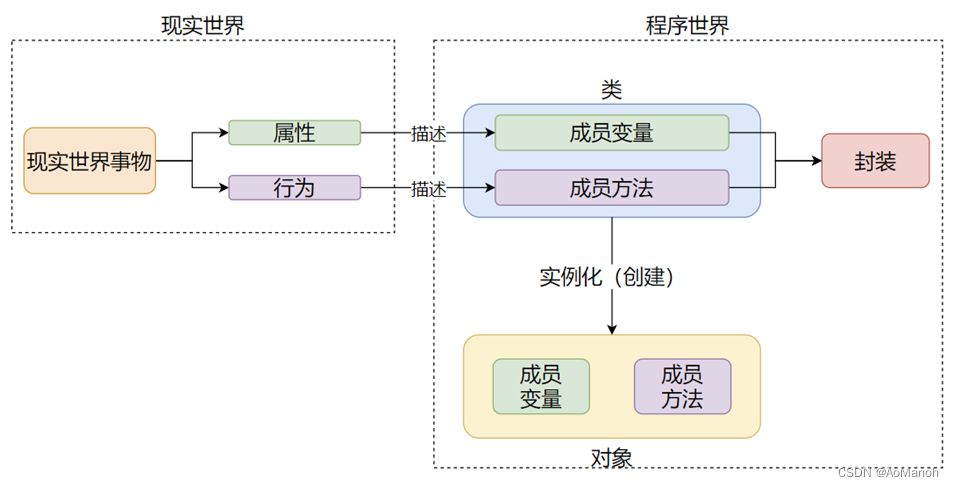
封装
学习目标:
1. 理解封装的概念
2. 掌握私有成员的使用
面向对象三大特性
面向对象编程,是许多编程语言都支持的一种编程思想
简单理解是:基于模板(类)去创建实体(对象),使用对象完成功能开发
面向对象包含的三大主要特征:
- 封装
- 继承
- 多态
封装
封装表示将现实世界事物的:
- 属性
- 行为
封装到类中,描述为:
- 成员变量
- 成员方法
从而实现程序对现实世界的描述
私有成员
既然现实世界事物有不公开的属性和行为,那么作为现实事物在程序中的映射的类,也应该支持
类中提供了私有成员的形式来支持
- 私有成员变量
- 私有成员方法
定义私有成员的方法非常简单,只需要:
- 私有成员变量:变量名以__开头(两个下划线)
- 私有成员变量:方法名以__开头(两个下划线)
即可完成私有成员的设置
代码案例
# 私有变量的创建
class Student:
__name = None
__age = None
def __check_name(self):
print("才不告诉你")
# 创建一个对象
stu = Student()
# 调用一下私有方法
stu.__check_name()
"""
运行结果:
Traceback (most recent call last):
File "D:\Python\learn\上课.py", line 2549, in <module>
stu.__check_name()
^^^^^^^^^^^^^^^^
AttributeError: 'Student' object has no attribute '__check_name'
"""
注意:
- 直接在外部修改私有成员变量不会报错,那是因为这个为对象创建了一个新的成员变量
使用私有成员
- 私有成员无法被类对象使用,但是可以被其他的成员使用
- 私有方法无法直接被类对象使用
- 私有变量无法赋值,也无法获取值
代码案例
# 私有成员方法访问私有成员变量
class Student:
__name_new = 'ikun'
__age = 18
def __check_name(self):
print(f"type(self.__name_new) = {type(self.__name_new)},"
f"type(self.__age) = {type(self.__age)},"
f"我是{self.__name_new}")
def judgement_age(self):
if self.__age < 18:
print("Access denied")
else:
print("Accept access" )
self.__check_name()
stu = Student() # 创建一个对象
stu.__age = 666 # 演示一下私有变量的赋值(不报错,但是是无效操作)
stu.judgement_age() # 调用一个可执行的成员方法
"""
运行结果:
Accept access
type(self.__name_new) = <class 'str'>,type(self.__age) = <class 'int'>,我是ikun
"""
总结
1. 封装的概念是指?
- 将现实世界事物在类中描述为属性和方法,即为封装。
2. 什么是私有成员?为什么需要私有成员?
- 现实事物有部分属性和行为是不公开对使用者开放的。同样在类中描述
- 属性和方法的时候也需要达到这个要求,就需要定义私有成员了
3. 如何定义私有成员?
- 成员变量和成员方法的命名均以_作为开头即可
4. 私有成员的访问限制?
- ·类对象无法访问私有成员
- ·类中的其它成员可以访问私有成员
私有成员的定义我们已经了解了,但是,有什么实际的意义吗?
在类中提供仅内部使用的属性和方法,而不对外开放(类对象无法使用)
练习:设计带有私有成员的手机

代码案例
# 设计带有私有成员的手机
class Phone:
__is_5g_enable = None # 私有成员变量
def __check_5g(self): # 私有成员方法——5g开关提示
if self.__is_5g_enable:
print("5g开启")
else:
print("5g关闭,使用4g网络")
def choose_open(self): # 公开成员方法——5g开关选择
if input("选择是否打开5g:yes/no = ") == 'yes':
self.__is_5g_enable = True
else:
self.__is_5g_enable = False
def call_by_5g(self): # 公开成员方法——通话提醒
self.choose_open()
self.__check_5g()
if not self.__is_5g_enable:
print("正在通话中")
people = Phone()
people.call_by_5g()
"""
运行结果:
选择是否打开5g:yes/no = no
5g关闭,使用4g网络
正在通话中
选择是否打开5g:yes/no = yes
5g开启
"""
继承
继承的基础语法
学习目标
**1. 理解继承的概念
- 掌握继承的使用方法
- 掌握pass关键字的作用**
继承分为:
- 单继承
- 多继承
继承表示:
- 从父类哪里继承(复制)来成员变量和成员方法
特别强调:不含私有!
小声bibi,类个人感觉还是把需要用的函数进行封装,然后分别划分到特定集合的类里,再在面向对象时调用这个包,使用里面的成员方法
这里直接演示一下多继承,单继承和多继承一样滴
代码案例
# 设计带有私有成员的手机
class Phone_5g_open_judgement_: # 私有成员方法——5g开关提示
is_5g_enable = None # 私有成员变量
def check_5g(self):
if self.is_5g_enable:
print("5g开启")
else:
print("5g关闭,使用4g网络")
class Phone_5g_open_choose: # 公开成员方法——5g开关选择
def choose_open(self):
if input("选择是否打开5g:yes/no = ") == 'yes':
self.is_5g_enable = True
else:
self.is_5g_enable = False
class Phone_welcome():
def welcome_5g(self):
print("原神,启动!" "\n" "原来,你也玩原神")
class Phone_inf(Phone_5g_open_judgement_, Phone_5g_open_choose, Phone_welcome): # 公开成员方法——通话提醒
def call_by_5g(self):
self.choose_open()
self.check_5g()
if not self.is_5g_enable:
print("正在通话中")
else:
self.welcome_5g()
class Phone(Phone_inf): # 演示一下单纯将所有类内容继承到一个类如何规范格式
pass
people = Phone()
people.call_by_5g()
"""
运行结果:
选择是否打开5g:yes/no = yes
5g开启
原神,启动!
原来,你也玩原神
选择是否打开5g:yes/no = no
5g关闭,使用4g网络
正在通话中
"""
那如果继承类里面有同名的变量或方法呢?
多个父类中,如果有同名的成员,那么默认以继承顺序(从左到右)为优先级——即:先继承的保留,后继承的被覆盖
总结
1. 什么是继承?
- 继承就是一个类,继承另外—个类的成员变量和成员方法
- 语法:
class类(父类[,父类2,......,父类N]):
类内容体
子类构建的类对象,可以:
- 有自己的成员变量和成员方法
- 使用父类的成员变量和成员方法
2. 单继承和多继承
- 单继承:一个类继承另一个类
- 多继承:一个类继承多个类,按照顺序从左向右依次继承
- 多继承中,如果父类有同名方法或属性,先继承的优先级高于后继承
3. pass关键字的作用是什么
- pass是占位语句,用来保证函数(方法)或类定义的完整性,表示无内容,空的意思
复写和使用父类成员
学习目标
**1. 掌握复写父类成员的语法
- 掌握䄦在子类中调用父类成员**
复写
子类继承父类成员属性和成员方法后,如果对其“不满意”,那么可以进行复写——即:在子类中重新定义同名的属性或方法
调用父类同名成员
一旦复写父类成员,那么类对象调用成员的时候,就会调用腹泻后的新成员。如果需要使用被复写的父类的成员,则需要特殊的调用方式:
- 调用父类成员
— 使用成员变量:父类名.成员变量
— 使用成员方法:父类名.成员方法(self)- 使用super调用父类成员
— 使用成员变量:super().成员变量
— 使用成员方法:super().成员方法()
代码案例(接上一节代码)
class Phone(Phone_inf): # 演示一下单纯将所有类内容继承到一个类如何规范格式
pass
phone_num = 415411
def welcome_5g(self):
print(f"调用复写后新成员方法:Phone.phone_num = {Phone.phone_num}")
print("调用复写后welcome_5g(self)方法:")
print("王者荣耀,启动!" "\n" "原来,你也玩王者荣耀")
# 调用父类原属性和父类方法一
print(f"调用父类属性:Phone_inf.phone_num = {Phone_inf.phone_num}") # 父类属性
print(f"调用父类方法:Phone_inf.welcome_5g(self) = ") # 父类方法
Phone_inf.welcome_5g(self)
# 调用父类原属性和父类方法二
print(f"调用父类属性:super.phone_num = {super().phone_num}") # 父类属性
print(f"调用父类方法:super.welcome_5g(self) = ") # 父类方法
super().welcome_5g()
"""
运行结果:
选择是否打开5g:yes/no = yes
5g开启
调用复写后新成员方法:Phone.phone_num = 415411
调用复写后welcome_5g(self)方法:
王者荣耀,启动!
原来,你也玩王者荣耀
调用父类属性:Phone_inf.phone_num = 114514
调用父类方法:Phone_inf.welcome_5g(self) =
原神,启动!
原来,你也玩原神
调用父类属性:super.phone_num = 114514
调用父类方法:super.welcome_5g(self) =
原神,启动!
原来,你也玩原神
"""
在这段代码中,我们将父类中的 Phone5g_open_judgement 类里成员变量phone_num = 114514 和 Phone_welcome类里的def welcome_5g(self) 成员方法进行了复写,复写后代码内容如上。在这段代码中,我们分别展示了两种调用父类的方法。
注意:
- 在外面调用不了原本父类的成员变量和方法。在外面能调用的是复写后的成员变量和方法
- 多继承情况下,如果出线条同名成员,使用super()方式调用父类成员时,优先匹配先继承的父类车成员(括号内继承的父类优先级从左往右降低)
- 第一种语法一定要记住self,第二种一定不要用self
总结
1. 复写表示:
- 对父类的成员属性或成员方法进行重新定义
2. 复写的语法:
- 在子类中重新实现同名成员方法或成员属性即可
3. 在子类中,如何调用父类成员:
方式1: 调用父类成员
- 使用成员变量:父类名.成员变量
- 使用成员方法:父类名.成员方法(self)
方式2: 使用super()调用父类成员
- 使用成员变量: super().成员变量
- 使用成员方法: super().成员方法()
- 注意:只可以在子类内部调用父类的同名成员,子类的实体类对象调用默认是
调用子类复写的
类型注解
变量的类型注解
学习目标:
**1. 理解为什么要使用类型注解
- 掌握变量的类型注解语法**
因为在我们在写一个大型项目的时候,常常会因为代码量过多,想要查看一个函数传参类型,或则是定义的变量类型,就得看好多东西,为了做到像IDE给出来封装好的方法里,可以按ctrl+p快速查看传参类型或变量类型,我们就引入了个类型注解
Python在3.5版本的时候引入了类型注解,以方便静态类型检查工具,IDE等第三方工具。
类型注解:
- 在代码中涉及数据交互的地方,提供数据类型的注解(显式的说明)
主要功能:
- 帮助第三方IDE工具(如PyCharm)对代码进行类型推断,协助做代码提示
- 帮助开发者自身对变量进行类型注释
支持:
- 变量的类型注解
- 函数(方法)形参列表和返回值的类型注解
我不是很建议容器详细注释,因为编译器有时候会抽风认为你在再给list、tuple之类的容器类型标注下标,属实有点难蹦,此外,在python3.9版本前,你想要注释还得导入包(前面容器下标也应该是这个原因),所以,还是比较麻烦的
下面分别展示一下各种类型注释的语法
为变量设置类型注释
基础语法:变量: 类型
基础数据类型注解
ikun_1: int = 666
ikun_2: str = '梅狸猫'
ikun_3: bool = True
类对象类型注解
class Student:
pass
stu: Student = Student()
基础容器类型注解
my_list: list = [666, '114514']
my_tuple: tuple = (666, '114514')
my_set: set = {666, '114514'}
my_dict: dict = {'树枝': 666, '荔枝': '114514'}
容器类型详细注解
# 首先就是得导入typing的包,pycharm里就可以找到
from typing import Dict, List, Tuple, Set, Union
my_list: List[int] = [666, 114514]
my_tuple: Tuple[int, str] = (666, '114514')
my_set: Set[Union[int, str]] = {666, '114514'}
my_dict: Dict[Union[str, int], str] = {'树枝': 666, '荔枝': '114514'}
注意:
- 元组类型设置类型详细注解,需要将每一个元素都标记出来
- 字典类型设置详细注解,需要两个类型。第一个是key,第二个事value(my_dict那个例子就详细展示出来了)
- 如果注释类型多种多样,那你就得用Union包容一下了
除了使用变量: 类型这种语法注释外,也可以在注释中进行类型注解
语法:# typle: 类型
在注释中进行注释
ikun_1: int = 666 # type: int
ikun_2: str = '梅狸猫' # type: str
ikun_3: bool = True # type: bool
类型注解的限制
类型注解主要功能在于:
- 帮助第三方IDE工具(如PyCharm)对代码进行类型推断,协助做代码提示
- 帮助开发者自身对变量进行类型注释(备注)
并不会真正的对类型做验证和判断
也就是,类型注解仅仅是提示性的,不是决定性的,所以下面这个案例也就不会报错了
var_1: int = "ikun"
var_2: str = 123
总结
1. 什么是类型注解,有什么作用?
- 在代码中涉及数据交互之时,对数据类型进行显式的说明,可以帮助:
- PyCharm等开发工具对代码做类型推断协助做代码提示
- ·开发者自身做类型的备注
2. 类型注解支持:
- 变量的类型注解
- 函数(方法)的形参和返回值的类型注解
3. 变量的类型注解语法
- 语法1:变量:类型
- 语法2:在注释中,# type:类型
4. 注意事项
- 类型注解只是提示性的,并非决定性的。数据类型和注解类型无法对应也不会
导致错误 - 在python3.9版本前,你想要注释还得导入typing包
函数(方法)的类型注解
学习目标:
**1. 掌握为函数(方法)形参进行类型注解
- 掌握为函数(方法)返回值进行类型注解**

函数和方法的形参类型注解语法:
def 函数方法名(形参名: 类型, 形参名: 类型, ......):
pass
因为比较简单,所以咱们直接用几个案例来掩饰一下就行
代码案例
def func(x: int = 0.4, y: float = 1) -> float:
return x + y
print(f"函数返回类型为:{type(func())},返回值为:{func()}")
print(f"函数返回类型为:{type(func(4, 1))},返回值为:{func(4, 1)}")
"""
运行结果:
函数返回类型为:<class 'float'>,返回值为:1.4
函数返回类型为:<class 'int'>,返回值为:5
"""
from typing import List,Tuple,Set
def func_list(data: List) -> List:
return data
tuple = (1, 1, 4, 5, 1, 4)
list = [1, 1, 4, 5, 1, 4]
print(f"函数返还类型为:{type(func_list(list))},返回内容为:{func_list(list)}")
print(f"函数返还类型为:{type(func_list(tuple))},返回内容为:{func_list(tuple)}")
"""
运行结果:
函数返还类型为:<class 'list'>,返回内容为:[1, 1, 4, 5, 1, 4]
函数返还类型为:<class 'tuple'>,返回内容为:(1, 1, 4, 5, 1, 4)
"""
从上面的代码案例可以看出来,注解不是强制性的,写的不对也没问题,就是给自己看的。另外,报错一定要导入typing这个包,导入的注释方法首字母一定要大写,需要啥导入啥,不然在pycharm中就会给你提示未使用import语句’xx’。
此外,有关这一节的内容可以参考下这篇文章:Python类型注解
总结
1. 函数(方法)可以为哪里添加注解?
- 形参的类型注解
- 返回值的类型注解
2. 函数(方法)的类型注解语法?
def 函数方法名(形参: 类型,......,形参: 类型) -> 返回值类型:
pass
注意,返回值类型注解的符号使用->
Union类型
学习目标:
**1. 理解Union类型
- 掌握使用Union进行联合类型注解**
关于这节类容,其实在变量和的类型注解这一节的代码案例中,就已经演示过,并且由于比较简单,所以下面就结合代码案例进行说明,从而掌握使用Union联合类型注解
语法:Union[类型,. .., 类型]
# 使用Union前,一定要先导入typing这个包(前面也提过)
# Union在变量中的运用
from typing import Union, Str, List, Tuple, Set, Dict
my_list: List[int] = [666, 114514]
my_tuple: Tuple[int, str] = (666, '114514')
my_set: Set[Union[int, str]] = {666, '114514'}
my_dict: Dict[Union[str, int], str] = {'树枝': 666, '荔枝': '114514'}
# Union在方法中的运用
from typing import Union
def func_Union(data: Union[str, int]) -> Union[str, int]:
return data * 2
print(f"函数返还类型为:{type(func_Union(666))},返回内容为{func_Union(666)}")
print(f"函数返还类型为:{type(func_Union('666'))},返回内容为{func_Union('666')}")
"""
运行结果:
函数返还类型为:<class 'int'>,返回内容为1332
函数返还类型为:<class 'str'>,返回内容为666666
"""
总结
1.什么是Union类型?
- 使用Union可以定义联合类型注解
2.Union的使用方式
- 导包: from typing import Union
- 使用: Union[类型,……类型]
3. 注意
- 再次强调Union的使用必须先导包
- 函数的返回值和你传入数据的类型有关
多态
学习目标:
**1. 理解多太多概念
- 理解抽象类(接口)的编程思想**
多态
什么是多态?
多态指的是多种状态,即完成某个行为时,使用不同的对象会得到不同的状态
说人话就是:同样的行为(函数),传入不同的对象,得到不同的状态
举个例子
代码案例
# 父类
class Animal:
def speak(self):
pass
# 子类一:狗叫
class Dog(Animal):
def speak(self):
print("刀哥太阳地")
# 子类二:猪叫
class Pig(Animal):
def speak(self):
print("笑出了猪叫")
# 开始写接口函数,用来实现同一标准speak
def make_speak(animal: Animal):
# 由于传入的参数是父类Animal,接受的对象是animal,所以animal自然可以调用父类定义的speak方法
animal.speak()
# 开始创建对象执行不同的speak方法
dog = Dog()
pig = Pig()
# 开始调用接口函数,使用同一标准的speak方法
make_speak(dog) # 传入执行Dog子类标准的dog对象
make_speak(pig) # 传入执行Pig子类标准的pig对象
'''
运行结果:
刀哥太阳地
笑出了猪叫
'''
从上面这个案例,Animal只是为了方便我们知道此函数调用的是父类,具体输入参数时,pycharm会补全此父类下的子类。此外,我们可以知道多态常用作在继承关系上
比如:
- 函数(方法)形参声明接受父类对象
- 实际传入父类的子类对象进行工作
即:
- 已父类做定义声明
- 以子类做实际工作
- 用同个方法获得同一行为的不同状态
抽象类(接口)
在上面的这个代码案例中,父类Animal的speak方法,是空实现
为什么要这样写呢?
- 父类用来确定有哪些方法:
- 具体的方法实现,由子类来自行决定
这种写法,就叫做抽象类(也可以称之为接口)
补充说明一下
抽象类: 含有抽象方法的类称之为抽象类
抽象方法: 方法体是空实现的(pass)称之为抽象方法
为什么要使用抽象类呢?
举个栗子
代码案例
# 创建一个抽象类(接口),用来制定空调的冷热风统一的标准
class Ac:
def cool_wind(self):
pass
def hot_wind(self):
pass
pass
# 现在我们是美的空调商,我们现在要执行这个标准
class Midea_Ac(Ac):
def cool_wind(self):
print("美的冷风已开启")
def hot_wind(self):
print("美的热风已开启")
# 现在我们是格力空调商,我们现在要执行这个标准
class Gree_Ac(Ac):
def cool_wind(self):
print("格力冷风已开启")
def hot_wind(self):
print("格力热风已开启")
# 现在开始设计遥控器,这个遥控器是通用的,那么我们就需要构建一个函数来调用一下美的和格力的接口函数
def make_cool(ac: Ac): # 调用冷风的函数
ac.cool_wind()
def make_hot(ac: Ac):
ac.hot_wind()
# 好了,现在开始使用遥控器——创建对象
midea_ac = Midea_Ac() # 使用美的空调的人
gree_ac = Gree_Ac() # 使用格力空调的人
# 现在,使用的人(创建的对象)要开始使用冷风热风功能了
midea_ac.cool_wind() # 使用美的空调的人开始使用遥控器的冷风按键了
midea_ac.hot_wind() # 使用美的空调的人开始使用遥控器的热风按键了
gree_ac.cool_wind() # 使用格力空调的人开始使用遥控器的冷风按键了
gree_ac.hot_wind() # 使用格力空调的人开始使用遥控器的热风按键了
"""
运行结果:
美的冷风已开启
美的热风已开启
格力冷风已开启
格力热风已开启
"""
在生活和实际应用中,父类引用指向子类对象,父类相当于目录,子类才是具体的章节内容。
在上面这个案例中,如果没有父类那两个空调商,就会使用两套标准,那后果就是你不能通过一个函数去同时调用两个空调(因为传参不同),必须要写两个函数去调用两个空调。
此外,在后续的项目工作中,大部分时候都是由上面的构建出抽象类,再把每一块内容分工出去,完善整体的框架(和作文相似,先写大纲,再写细节)
总结
1. 什么是多态?
- 多态指的是,同一个行为,使用不同的对象获得不同的状态。如:定义函数(方法),通过类型注解声明需要父类对象,实际传入子类对象进行工作,从而获得不同的工作状态
2. 什么是抽象类(接口)
- 包含抽象方法的类,称之为抽象类。抽象方法是指:没有具体实现的方法(pass)称之为抽象方法
3. 抽象类的作用
- 多用于做顶层设计(设计标准),以便子类做具体实现。
- 也是对子类的一种软性约束,要求子类必须复写(实现)父类的一些方法
并配合多态使用,获得不同的工作状态。
SQL入门和实战
本大章只是简单入门,满足后续案例需要计科(即增删改查),如果想要深入学习,就可以去我的另一篇学习笔记查看 (超链接——暂时空着)
数据库介绍
学习目标:
**1. 理解数据库的作用
- 了解常见的数据库软件**
数据库就是存储数据的库,那么数据库如何组织数据?
简单来讲,一般都是按照库——表——数据这三个层级来组织的
那么如何实现这种数据库形式的数据管理呢?
可以借助数据库管理系统,也就是常说的数据库软件。如:MySQL、PostgreSQL、甲骨文、SQLServer等等
这些软件都能实现:管理库、管理表、基于表来管理数据
数据库和SQL的关系
数据库是用来存储数据的,在这个过程中,会涉及到:
- 数据的新增
- 数据的删除
- 数据的修改
- 数据的查询
- 数据库、数据表的管理
等等
而SQL语言,就是—种对数据库、数据进行操作、管理、查询的工具。
使用数据库软件去获得库->表->数据,这种数据组织、存储的能力并借助SQL语言,完成对数据的增删改查等操作
总结
1. 数据库是什么?有什么作用呢?
- 数据库就是指数据存储的库,作用就是组织数据并存储数据。
2. 数据库如何组织数据呢?
- 按照:库->表->数据三个层级进行组织
3. 数据库软件是什么?
- 我们学习哪种数据库软件呢?数据库软件就是提供库->表->数据,这种数据组织形式的工具软件,也称之为数据库管理系统
- 常见的数据库软件有:Oracle、MySQL、SQL Server、PostgreSQL.sQLite,课程以MySQL软件为基础进行学习
4. 数据库和SQL的关系是?
- 数据库(软件)提供数据组织存储的能力SQL语句则是操作数据、数据库的工具语言
MySQL的安装
学习目标:
1. 掌握在Windows系统中安装MySQL数据库
MySQL的版本
针对不同的用户,MySQL分为两种不同的版本:
免费:
- MysQL Community Server
社区版本,免费,但是Mysql不提供官方技术支持。 - MysQL Cluster
集群版,开源免费,可将几个MySQL Server封装成一个Server。
收费:
- MySQL Enterprise Edition
商业版,该版本是收费版本,可以试用30天,官方提供技术支持 - MysQL Cluster CGE
高级集群版,需付费。
MySQL的安装
这里咱们演示一下如何安装Windows系统下的MySQL社区版
首先,打开浏览器搜索MySQL或者直接在地址搜索处搜索domnload.mysql.com
如果嫌麻烦,点击这个链接:MySQL Install for Windows
在当前页找到第二个download下载离线版(包大的那个就是),下载并安装,等待一会儿后会弹出来一个安装页面
在这里我们不建议选择默认安装,默认会直接安装到C盘(当然C盘足够直接安装也可以),所以我们这里选择自定义安装Custom,选择好了后点击next(下一步)
点击MySQL-x64,然后点击绿色的箭头添加进右边的Products To Be Install,点击一下添加过来的MySQL Severs x64,在下方就会出现一行蓝色的小字Advanced Options,点击后一下出现下面这个界面
第一个Install Directory是MySQL的安装路径,第二个就是数据存放路径,在这之前我已经在我的D盘上创建了一MySQL文件夹,里面分别创建了Install和data两个文件,所以我这里显示的是已经更改路径后的安装地址了。
点击OK开始安装,会弹出来一个Warning,别管他,点ok继续就是了。确定路径后,点击next,出现下面这个界面
点击next,继续点击Yes出现下面这个界面
点击Execute,安装环境,下载好了,点击next,还是next进入到这个界面
默认的就行,所以点击next进入到Authentication Method环节,选择默认的就行,继续点击next,进入Accounts and Roles环节,设置一个自己的管理员密码即可
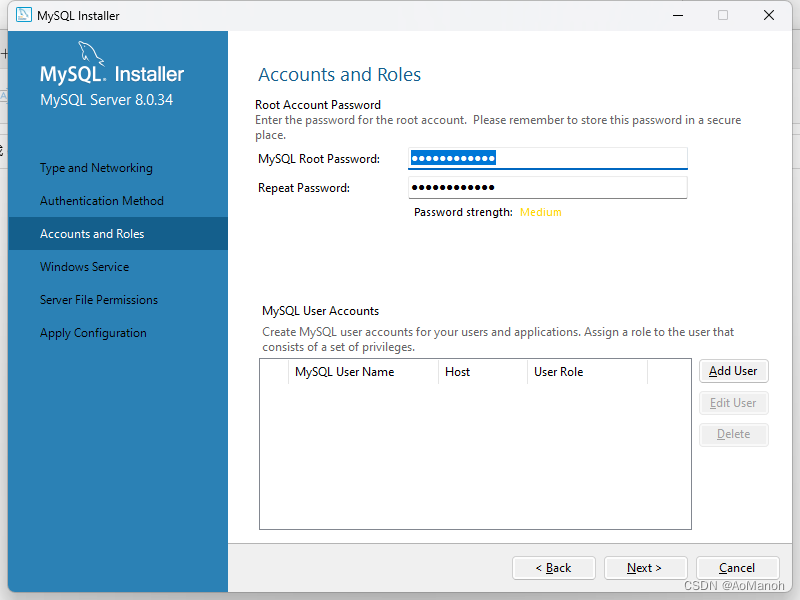
点击next进入下一环节Windows Service,账户名字看你自己,默认就行,记住电脑名称或组名要英文,不能出现中文,会出错的。然后点击next进入下一环节Server File Permissions,这个环节是8.0.32才出现的,让你再次确定是否安装到当前目录并且以后在这个目录更新数据,选择默认就可以了。
下一步,在Apply Configuration环节安装东西,点击Execute等待安装完成即可。安装完成,点击finish,点击next,然后就安装完毕了。
配置环境变量
开始MySQL的配置,首先先打开MySQL的安装文件夹,以为我安装在了D盘,所以直接打开MySQL文件里的Install文件,打开bin文件,然后复制这段路径,如下图所示

然后点击Win键,在搜索栏搜索查看高级系统设置,出现下面这个界面
点击环境变量,在系统变量里找到变量Path,双击一下,出现编辑环境变量界面,点击新建,把刚才复制的文件路径D:\MySQL\Install\bin粘贴进去,点击确定,环境配置也完成了。
然后咱们来检测一下是否安装成功
Win+R打开运行cmd,然后在命令提示符里输入mysql -uroot -p,这个表示以root用户进行登录,然后就是回车,会显示Enter password:,输入你的密码,回车键确定,出现下面这个界面就表明安装成功
至此,你的MySQL数据库就安装成功、环境配置成功且能正常运行了。
MySQL的入门使用
学习目标:
1. 掌握使用图形化工具操作MySQL数据库软件
MySQL安装好后,就可以简单的尝试使用它。
打开:命令提示符程序,输入:mysql -uroot -p,然后回车后输入密码,即可进入命令行环境
在MySQL的命令行环境下,可以通过:
- show databases;查看有哪些数据库
- use数据库名,使用某个数据库
- show tables查看数据库内有哪些表
- exit退出MySQL的命令行环境
等基础命令。
这些命令就是后面我们要学习的SQL语言
使用图形化工具操作MySQL
当然,通过命令提示符进行MySQL操作,不是很方便,所以一般我们都会使用第三方的图形化工具进行使用
可用于MySQL的图形化工具非常多,下面我们介绍一个跨平台、开源、免费的图形化工具:Dveaver,不仅可以在网页中下载,微软也可以下载
ps:这里给一个Navicat 16破解版和DBeaver-ue23.00破解版的安装流程Navicat 16破解安装 ,DBeaver-ue23.00破解版
SQL基础与DDL
学习目标:
**1. 对SQL语言有基础的认知
- 掌握SQL语言的分类
- 掌握基础的DDL语法**
SQL全称:Structured Query Language,结构化查询语言,用于访问和处理数据库的标准的计算机语言。
SQL语言的分类
由于数据库管理系统(数据库软件)功能非常多,不仅仅是存储数据,还要包含:数据的管理、表的管理、库的管理、账户管理、权限管理等等。
所以,操作数据库的SQL语言,也基于功能,可以划分为4类:
- 数据定义:DDL (Data Definition Language)
- 库的创建删除.表的创建删除等
- 教据操纵:DML (Data Manipulation Language)
- 新增数据、删除数据.修改数据等
- 教据控制:DCL (Data Control Language)
- 新增用户、删除用户、密码修改.权限管理等
- 数据查询:DQL (Data Query Language)
- 基于需求查询和计算数据
SQL的语法特征
在学习DDL、DQL等之前,我们先来了解SQL的语法特征。
- SQL语言,大小写不敏感
- SQL可以单行或多行书写,最后以;号结束
- SQL支持注释:
- 单行注释:—注释内容(—后面一定要有一个空格)
- 单行注释:# 注释内容(#后面可以不加空格,推荐加上)
- 多行注释:/ 注释内容 /
此外,MySQL标准语句就是全部大写,小写会在编译时自动转换为大写
DDL-库管理
现在来简单学习一下数据库管理的相关SQL
# 查看数据库:
SHOW DATABASES;
# 使用数据库:
USE 数据库名称;
# 创建数据库:
CREATE DATABASE 数据库名称 [CHARSET UTF8];
# 删除数据库:
DRIO DATABASE 数据库名称;
# 查看当前使用的数据库:
SELECT DATABASE();
在上面语法中,方括号表示括号内的内容可以不写,当然,你要写记住一定不能带方括号,比如:
create database test charset uft8;
或则
CREATE DATABASE test CHARSET UTF8;
DDL-表管理
# 查看有哪些表:
SHOW TABLES;
# 删除表:
DROP TABLE 表名称;**
DROP TABLE IF EXISTS 表名称;**
# 创建表:
CREATE TABLE 表名称(
列名称 列类型,
列名称 列类型
......
)
其中,列类型有:

此外,在进行表操作的时候必须要先选择数据库,下面举个例子:
代码展示
CREATE DATABASE test CHARSET UTF8; # 创建一个数据库
USE test; # 使用数据库
SHOW TABLES; # 展示这个数据库中的所有表
create table student(
id int,
name varchar(10), # 文本,长度为数字,做最大长度限制
age int # 年龄
);
然后,你就能在左边看见你创建的表了,双击student就能查看表的具体内容
总结
1. SQL语言是什么?有什么作用?
- SQL:结构化查询语言,用于操作数据库,通用于绝大多数的数据库软
件
2. SQL的特征.大小写不敏感
- 需以;号结尾
- 支持单行、多行注释
3. SQL语言的分类. DDL数据定义
- DML数据操作. DCL数据控制
- DOL数据杳询
SQL - DML
学习目标:
**1. 掌握DML: INSERT数据插入
- 掌握DML: DELETE数据删除
- 掌握DML: UPDATE数据更新**
DML
DML是指数据操作语言,英文全称是Data Manipulation Language,用来对数据库中表的数据记录进行更新。
关键字:
- 插入INSERT
- 删除DELETE
- 更新UPDATE
插入数据 INSERT
基础语法:
INSERT INTO 表 (列1, 列2......, 列N) VALUES (列1, 列2......, 列N), ..., (列1, 列2......, 列N);
代码案例
# 创建一个student表格
CREATE TABLE student(
id INT,
name VARCHAR(10),
age INT,
gender VARCHAR(10)
);
# 创建人物信息
# 插入全部信息就不用再student后面注明
INSERT INTO student VALUES (1, 'ikun', 18, '男');
INSERT INTO student VALUES (2, '树枝', 666, '男');
# 插入部分信息
INSERT INTO student(id, name, age) VALUES (3, '梅狸猫', 6);
INSERT INTO student(id, name, age) VALUES (4, '荔枝', 114514);
# 插入全部信息
INSERT INTO student(id, name, age, gender) VALUES (5, '香精煎鱼', 18, '女');
INSERT INTO student(id, name, age, gender) VALUES (6, '油饼', 12, '男');
注意:
- 插入字符串数据,需要用单引号包围
- 插入全部列的时候,列的列表可以省略
- 插入的成员信息可以不完整
数据删除 DELETE
基础语法:
DELETE FROM 表名称 [WHERE 条件判断];

代码案例
# 删除name = ikun的数据————ikun被删除
DELETE FROM student WHERE name = 'ikun';
# 删除age = 18和 name = 梅狸猫————梅狸猫和香精煎鱼和ikun被删除
DELETE FROM student WHERE name = '梅狸猫' OR age = 18;
# 删除同时满足gender = 男,age > 18————树枝被删除
DELETE FROM student WHERE gender = '男' AND age > 18;
# 删除所有成员
DELETE FROM student;
数据更新 UPDATE
基础语法:
UPDATE 表名 SET 列=值 [WHERE 条件判断];
其中,条件判断和前面删除的时候一样
代码案例
# 将之前梅狸猫和荔枝的性别gender进行更新
UPDATE student SET gender = '女' WHERE name = '梅狸猫' OR name = '荔枝';
# 将所有的年龄age更新为666
UPDATE student SET age = 666;
SQL-DQL
学习目标:
**1. 掌握DQL:SELECT语句进行基础的数据查询
- 掌握DQL:GROUP BY进行分组聚合查询
- 掌握DQL:对查询结果进行排序分页**
基础查询
基础数据查询
在SQL中,通过SELECT关键字开头的SQL语句,来进行数据的查询
基础语法:
SELECT 字段列标|* FROM 表;含义就是:
从(FROM)表中,选择(SELECT)某些列进行展示
数据查询——过滤
查询也可以带有指定的提哦啊见,语法如下:
SELECT 字段列表|* FROM 表 WHERE 条件判断;
代码案例
# 查看表格所有数据
SELECT * FROM student;
# 查看表格中某一类数据——如性别为男的数据
SELECT * FROM student WHERE gender = '男';
分组聚合
分组聚合应用场景非常多,如:统计班级中,男生和女生的
人数。
这种需求就需要:
- 按性别分组
- *统计每个组的人数这就称之为:分组聚合。
基础语法:
SELECT 字段|聚合函数 FROM 表 WHERE 条件 GROUP BY 列;
聚合函数:
- SUM(列)——求和
- AVG列) —— 求平均值
- MIN(列) —— 求最小值
- MAX(列) ——求最大值
- COUNT(列 | *) —— 求数量
SELECT gender, AVG(age) FROM student GROUP BY gender;
# 按照年龄进行分类——从表中,按照年龄划分,找出年龄>16的人,并统计每个年龄段的数量
SELECT age, COUNT(*) FROM student WHERE age>16 GROUP BY age;
# 按照性别划分——从表中,按照性别划分,求出男女平均年龄,找出最大/最小年龄,以及统计男生女生人数
SELECT gender , AVG(age), MAX(age), MIN(age), COUNT(*) FROM student GROUP BY gender;
注意: SELECT中,除了聚合函数外,GROUP BY了那个列,那个列才能出现在SELECT中,不然就会出现歧义!此外,WHERE不包含聚合函数,也就是下面这个语句是无效的
# 按照年龄进行分组,将年龄大于平均年龄的成员段数进行统
SELECT age, COUNT(*) FROM student WHERE age>AVG(age) GROUP BY age;
排序分页
可以对查询的结果使用ORDER BY关键字,指定某个列进行排序,语法:
# 基础语法:
SELECT 列|聚合函数|* FROM 表;
# 扩展应用:
WHERE ...
GROUP BY ...
ORDER BY ...[ASC | DESC]
注意: ASC表示升序排序,DESC表示降序排序,当我们使用ORDER BY关键字时,不写ASC/DESC就是默认ASC生序排序
代码案例
# 按照序号,对所有人进行降序排序
SELECT * FROM student ORDER BY id DESC;
# 按照年龄,对年龄大于8岁小于666的人进行生序排序
SELECT * FROM student WHERE age > 8 AND age < 666 ORDER BY age;
结果分页限制
同样,可以使用LIMIT关键字,对查询结果进行数量限制或分页显示,语法:
SELECT 列|聚合函数|* FROM 表 LIMIT n[, m]
其中:
- LIMIT n:表示在整个表中,只查询前n个(包括n)
- LIMIT n,m:表示在整个表中,从第n个开始查询,演示第n个后m个内容(不包括n)
代码案例
# 查询前4个内容——即id = 1,2,3,4
SELECT * FROM student LIMIT 4;
# 从第一个开始,查询后三个成员——即id = 2,3,4
SELECT * FROM student LIMIT 1, 3;
# 按照年龄进行分组,统计年龄在16 < age < 114514里,每个年龄段的人数,并且对统计出来的结果按照年龄从大到小降序,最终显示前两条排序结果
# 写法一:一句拉通
SELECT age, COUNT(*) FROM student WHERE age>16 AND age < 114514 GROUP BY age ORDER BY age DESC LIMIT 0,2;
# 写法二:分段续写
SELECT age, COUNT(*) FROM student
WHERE age>16 AND age < 114514
GROUP BY age
ORDER BY age DESC
LIMIT 0,2;
在上面这个案例中,写法二就比较清晰的展示了整个语法逻辑的层次,即下面这幅图:
只要不用 ;(分号),就不会被判定为语句结束
总结
1. 排序和分页限制的语法是?

2. 截止到目前学习到的关键字,需注意:
- WHERE、GROUP BY、ORDER BY、LIMIT均可按需求省略
- SELECT和FROM是必写的
- 执行顺序:FROM -> WRERE -> GROUP BY和聚合函数->SELECT -> ORDER BY ->LIMIT
python & MySQL
基础使用
学习目标:
1. 掌握python执行SQL语句操作MySQL数据库软件
pymysql
除了使用图形化工具以外,我们也可以使用编程语言来执行SQL从而操作数据库。
在Python中,使用第三方库: pymysql来完成对MySQL数据库的操作。
Win+R调出运行,输入cmd调用命令提示符,然后再输入pip install pymysql安装即可
创建到MySQL的数据库连接
代码如下:
# 创建MySQL数据库连接
from pymysql import Connection
# 获取到MySQL数据库的连接对象
conn = Connection(
host='localhost', # 主机名(或ip地址)
port=3306, # 端口,默认为3306
user='root', # 账户名
password='020926ouhao.' # 密码
)
# 打印MySQL数据库软件信息
print(conn.get_server_info())
# 关闭数据库的连接
conn.close()
'''
运行结果:8.0.34(MySQL版本号)
'''
如果出现问题,这里给出几个解决方法:
以管理员身份运行cmd,注意是管理员身份,输入net start mysql180就行了
host可以写成127.0.0.1
如果报错,可以试一下安装cryptography这个包,命令提示符里输入 pip install cryptography安装即可
执行SQL语句
下面演示一下执行非查询性的SQL语句:
代码案例
# 查看数据库是否连接成功,连接成功返回MySQL数据库版本
try:
# 创建MySQL数据库连接
from pymysql import Connection
# 获取到MySQL数据库的连接对象
conn = Connection(
host='localhost', # 主机名(或ip地址)
port=3306, # 端口,默认为3306
user='root', # 账户名
password='******' # 密码
)
# 执行非查询性SQL,获取游标对象
cursor = conn.cursor()
# 选择数据库
conn.select_db("test_mysql")
# 成功后返回版本号
print(conn.get_server_info())
# 如果数据库连接失败,语句提醒
except Exception as e:
print("数据库连接失败!")
# 如果数据库连接成功,开始执行SQL语句
else:
# 执行sql,删除以前的表格
cursor.execute("DROP TABLE IF EXISTS test_pymysql; ")
# 第一种写法,执行sql,创建一个表格
# cursor.execute("create table test_pymysql(id int, name varchar(10), gender varchar(10), age int;")
# 第二种写法,如果写一排层次不太清晰,就可以这么写
cursor.execute(
"create table test_pymysql"
"("
"id int,"
"age int,"
"name varchar(10),"
"gender varchar(10)"
");"
)
# 最后,无论是否连接成功,关闭数据库的连接
finally:
conn.close()
在上面这个代码案例中,演示了try——except语句的应用,并且演示了如何在pycharm中通过控制光标函数execute去控制光标书写SQL语句
下面演示一下,执行查询性质的SQL语句——DELETE
# 使用游标对象,执行SQL查询表格语句
cursor.execute("select * from student")
# 查询后,需要先通过fetchall方法获取所有查询结果,然后通过变量去接受查询结果
results = cursor.fetchall() # type: tuple —— 提醒自己一下返回结果数据容器为tuple
# 开始循环输出每一行表格内容
for line in results:
print(line)
注意:
- 游标对象使用fetchall()方法后,得到的是全部的查询结果,数据容器是一个元祖
- 这个元祖内嵌套了元组,嵌套的元组就是一行的查询结果
总结
1.Python中使用什么第三方库来操作MySQL?如何安装?
- 使用第三方库为:pymysql
- 安装:pip install pymysql2
2. 如何获取链接对象?
- from pymysql import Connection 导包
- Connection(主机,端口,账户,密码)即可得到链接对象
- 链接对象.close()关闭和MySQL数据库的连接
3. 如何执行SQL查询
- 通过连接对象调用cursor()方法,得到游标对象
- 游标对象.execute()执行SQL语句
- 游标对象.fetchall()得到全部的查询结果封装入元组内
数据插入
学习目标:
- 掌握python语句执行SQL语言插入数据到MySQL
先来看一段代码案例
# 导入库
from pymysql import Connection
# 构建到MySQL数据库的链接
coon = Connection(
host = 'localhost', # 主机名(IP)
port = 3306 # 端口
user = "root" # 账户
password = "******" # 密码
)
# 获取游标对象
cursor = conn.cursor()
# 选择数据库
conn.select_db("test_mysql")
# 执行sql语句
cursor.execute(
"insert into student values(7, '川屎腐', 20, '男')"
)
# 关闭连接
conn.close()
如图所示代码,经过执行是无法将数据插入到数据库student中的
pymysql在执行数据插入或其他产生数据更改的SQL语句时,默认是需要提交更改的。即需要通过代码“确认”这种梗该行为
如何解决呢?
通过链接对象.commit()即可以确认此行为
代码案例
cursor.execute(
"insert into student values(7, '川屎腐', 20, '男')"
)
conn.commit()
当然,很多时候改一句确认一句比较耗时,如果不想手动commit确认,可以在构件连接对象的时候,设置自动commit的属性,如下面代码所示:
conn = Connection(
host = 'localhost',
port = '3306',
user = 'root',
password = '******',
autocommit = True
)
如上代码所示,我们只需要加一句 autocommit = True,即可自动提交无需手动commit了
综合案例
学习目标:
1. 使用SQL语句和pymysql库完成综合案例的开发
案例需求
我们使用《面向对象》章节案例中 的数据库,完成使用python语言,读取数据,并将数据写入mysql的功能
DDL定义
- 本次需求开发,我们需要新建一个数据库来使用,数据库名称:py_sql
- 基于数据结构,可以得到建表语句:
CREATE TABLE order(
order_data DATE,
order_id VARCHAR(225),
money INT,
provence VARCHAR(225)
);
本项目大致流程:读取数据 -> 封装数据对象 -> 构建数据库链接 -> 写入数据库
第一步,先在MySQL数据库软件里创建一个数据库存放内容
# 如果有这个库,咱们先删除这个库
DROP DATABASE If EXISTS py_sql;
# 没有库,创建一个名字叫py_sql的数据库,编码格式是UTF-8
CREATE DATABASE py_sql CHARSET UTF8;
# 开始使用这个库
USE py_sql;
# 如果存在orders这个表,那就删除
DROP TABLE IF EXISTS orders;
# 构建一个基本的表容纳订单信息
CREATE TABLE orders(
order_date DATE,
order_id VARCHAR(255),
money FLOAT,
provence VARCHAR(10)
);
然后,后面就是在python上读取文件数据,然后封装数据了
这里我们先链接数据库,然后,这里我为了方便,把在MySQL中删除表和创建表的语句放在了python中
# 导入数据库pymysql包
from pymysql import Connection
# 链接MySQL数据库
conn = Connection(
host='localhost', # 主机名(ip)
port=3306,
user='root',
password='020926ouhao.',
autocommit=True
)
# 执行非查询行SQL语句,获取光标
cursor = conn.cursor()
# 连接一下数据库
conn.select_db("py_sql")
# 如果链接没问题,咱们返回一下版本号
print(conn.get_server_info())
# 如果存在orders这个表,那就删除
cursor.execute("DROP TABLE IF EXISTS orders;")
# 不存在就创建orders表格
cursor.execute(
"create table orders("
"order_date DATE,"
"order_id VARCHAR(255),"
"money FLOAT,"
"provence VARCHAR(10)"
");"
)
ok,到这里已经可以开始写入数据了,面对这一部分,我最开始的想法是将每一行的文件内容提取出来,然后观察发现,每个数据内容是用逗号分隔开的,所以我通过split函数处理一下逗号,从而将每一行的文件数据转化为了每一行的字符串列表。最后再通过外循环获取到每一行文件内容,内循环进行SQL语句的撰写,然后通过光标函数execute将每一句撰写好的SQL语句格式化后输出,从而实现将数据写入数据库的表中
# 获取文件内容
with open('D:/Python/learn/2011_1_sales.txt', 'r', encoding='UTF-8') as f:
# 读取文件的每一行内容,将内容存放在变量line中
for line in f: # type: str
# 通过split分割文件line的内容,并将其存入字符串line_list中
line_list = line.split(",") # type: list[str]
# 遍历字符串line_list的内容,内容依次为order_date、order_id、money、provence
for i in range(0, 4): # type: int
# 创建一个字符串变量,这个字符串变量就是我们要用的SQL语句
sql = f"insert into orders values(" \
f"'{line_list[0]}', '{line_list[1]}', {line_list[2]}, '{line_list[3]}')"
# 输入SQL语句
cursor.execute(f"{sql}")
别忘记关闭链接奥,最终代码如下:
代码案例一
# 查看数据库是否连接成功,连接成功返回MySQL数据库版本
try:
# 导入数据库pymysql包
from pymysql import Connection
# 链接MySQL数据库
conn = Connection(
host='localhost', # 主机名(ip)
port=3306,
user='root',
password='020926ouhao.',
autocommit=True
)
# 执行非查询行SQL语句,获取光标
cursor = conn.cursor()
# 连接一下数据库
conn.select_db("py_sql")
# 如果链接没问题,咱们返回一下版本号
print(conn.get_server_info())
except Exception as e:
print(f"wrong fistly!info = {e}")
else:
# 开始导入销售账单
try:
# 如果存在orders这个表,那就删除
cursor.execute("DROP TABLE IF EXISTS orders;")
# 不存在就创建orders表格
cursor.execute(
"create table orders("
"order_date DATE,"
"order_id VARCHAR(255),"
"money FLOAT,"
"provence VARCHAR(10)"
");"
)
# 获取文件内容
with open('D:/Python/learn/2011_1_sales.txt', 'r', encoding='UTF-8') as f:
# 读取文件的每一行内容,将内容存放在变量line中
for line in f: # type: str
# 通过split分割文件line的内容,并将其存入字符串line_list中
line_list = line.split(",") # type: list[str]
# 遍历字符串line_list的内容,内容依次为order_date、order_id、money、provence
for i in range(0, 4): # type: int
# 创建一个字符串变量,这个字符串变量就是我们要用的SQL语句
sql = f"insert into orders values(" \
f"'{line_list[0]}', '{line_list[1]}', {line_list[2]}, '{line_list[3]}')"
# 输入SQL语句
cursor.execute(f"{sql}")
except Exception as e:
print(f"wrong secondly! info = {e}")
finally:
conn.close() # 关闭链接
代码案例二
from pymysql import Connection
# 链接MySQL
conn = Connection(
host='localhost',
port=3306,
user='root',
password='020926ouhao.',
autocommit=True
)
# 获取光标
cursor = conn.cursor()
# 开始创建SQL数据库
cursor.execute("drop database if exists py_sql;") # 如果存在py_sql这个数据库,就删除
cursor.execute("create database py_sql charset utf8;") # 创建py_sql这个数据库
cursor.execute("use py_sql;") # 连接数据库
cursor.execute("drop table if exists orders;") # 如果存在orders这个表,就先删除
cursor.execute(
"create table orders(" # 创建orders这个表
"order_date DATE,"
"order_id VARCHAR(255),"
"money FLOAT,"
"provence VARCHAR(10)"
");"
)
# 打开文件,导入数据
with open("D:/Python/learn/2011_1_sales.txt", "r", encoding="UTF-8") as f:
# 创建类,通过构造方法获取四个数据,再通过字符串方法转换为str输出内容
class orders:
def __init__(self, order_date, order_id, money, provence):
self.order_date = order_date
self.order_id = order_id
self.money = money
self.provence = provence
def __str__(self):
return f"'{self.order_date}', '{self.order_id}', {self.money}, '{self.provence}'"
# 通过循环读取内容,并通过split将每一行数据分割成order_date,order_id,money,provence四份数据,再传入order_line这个对象中
for line in f:
line = line.split(',')
order_line = orders(line[0], line[1], line[2], line[3])
# 每次将order_Line对象内容传入光标
cursor.execute(f"insert into orders values ({order_line});")
# 查看表格
cursor.execute("select * from orders;")
# 获取表格内容
for line in cursor.fetchall():
print(line)
# 关闭链接
conn.close()
代码案例三
from pymysql import Connection
# 链接MySQL
conn = Connection(
host='localhost',
port=3306,
user='root',
password='020926ouhao.',
autocommit=True
)
# 获取光标
cursor = conn.cursor()
# 开始创建SQL数据库
cursor.execute("drop database if exists py_sql;") # 如果存在py_sql这个数据库,就删除
cursor.execute("create database py_sql charset utf8;") # 创建py_sql这个数据库
cursor.execute("use py_sql;") # 连接数据库
cursor.execute("drop table if exists orders;") # 如果存在orders这个表,就先删除
cursor.execute(
"create table orders(" # 创建orders这个表
"order_date DATE,"
"order_id VARCHAR(255),"
"money FLOAT,"
"provence VARCHAR(10)"
");"
)
# 打开文件,导入数据
with open("D:/Python/learn/2011_1_sales.txt", "r", encoding="UTF-8") as f:
# 通过split分割每行文件的内容,然后再将返还成为列表的每行内容依次通过下标提取,提取后在以字符串的形式给order_line
for line in f:
line = line.split(',')
order_line: str = f"'{line[0]}', '{line[1]}', {line[2]}, '{line[3]}'"
# 每次将order_Line对象内容传入光标
cursor.execute(f"insert into orders values ({order_line});")
# 查看表格
cursor.execute("select * from orders;")
# 获取表格内容
for line in cursor.fetchall():
print(line)
# 关闭链接
conn.close()
代码案例四
这个案例是演示如何快速拿出数据库表格内容并写入文件
# 引入一个库文件,方便产生重复文件时删除重复文件
import os
from pymysql import Connection
# 链接MySQL
conn = Connection(
host='localhost',
port=3306,
user='root',
password='020926ouhao.',
autocommit=True
)
# 获取光标
cursor = conn.cursor()
# 链接需要取出数据的数据库
cursor.execute("use test_mysql;")
# 调用该数据库中的表
cursor.execute("select * from student;")
# 获取表中内容
# content = cursor.fetchall()
if os.path.exists("D:/Python/learn/test_mysql.txt"): # 如果存在这个文件,就删除
os.remove("D:/Python/learn/test_mysql.txt")
else: # 不存在时略过
pass
with open("D:/Python/learn/test_mysql.txt", 'a', encoding='UTF-8') as f:
for line in cursor.fetchall():
print(line)
f.write(str(line) + '\n')
conn.close()
python高阶技巧
闭包
学习目标:
- 掌握闭包的用途和用法
- 掌握nonlocal关键字的作用
先看一个代码案例
# 账户余额
def atm(num, deposit=True):
global account_amount
if deposit:
account_amount += num
print(f"存款:+{num},账户余额:{account_amount}")
else:
account_amount -= num
print(f"取款:-{num},账户余额:{account_amount}")
atm(300)
atm(300)
atm(100, False
在上面这个案例中,我们通过全局变量account_amount来记录余额
尽管功能可以实现,但是存在以下问题:
- 代码在命名空间上(变量定义)不够干净、整洁
- 全局变量有被修改的风险
如何解决?
- 将变量定义在函数内部是行不通的
- 我们需要使用闭包
在函数嵌套的前提下,内部函数使用了外部函数的变量,并且外部函数返回了内部函数,我们把这个使用外部函数变量的内部函数称为闭包
代码案例
# 账户余额
def account_create(initial_amount = 0):
def atm(num, deposit=True):
nonlocal initial_amount
if deposit:
initial_amount += num
print(f"存款:+{num},账户余额:{initial_amount}")
else:
initial_amount -= num
print(f"取款:-{num},账户余额:{initial_amount}")
return atm
fn = account_create()
fn(300)
fn(300)
fn(100, False)
'''
运行结果:
存款:+300,账户余额:300
存款:+300,账户余额:600
取款:-100,账户余额:500
'''
所谓闭包,就是让内层函数使用外层变量,从而减少全局变量的使用。
拿上面这个代码代码案例来讲,我们在依赖外部全局变量,但是又不想定义外部全局变量的时候(外部全局变量也就在函数内会调用,定义起来不就显得有点多余了吗?),外部函数里的initial_amount充当起了内部函数atm的外部变量,在我们向account_create传参的时候,我们传入多少次这个外部变量都存在,但是这个外部变量又不会被人为篡改。
内部函数能访问这个外部变量,外部变量又不会被修改,这就是闭包
既然initial_amount作为外部变量存在,那么atm函数能否修改这个变量呢?
我们只需要使用nonlocal关键字修饰外部函数变量就能够在内部函数中修改
闭包注意事项
优点:
- 无需定义全局变量即可实现通过函数,持续的访问、修改某个值
- 闭包使用的变量的所用于在函数内,难以被错误的调用修改
- 返回的是内部函数,所以外部函数就是一个外部参数,真正起作用的还是在内部函数
缺点:
- 由于内部函数持续引用外部函数的值,所以会导致这一部分内存空间不被释放,一直占用内存
总结
1. 什么是闭包
- 定义双层嵌套函数,内层函数可以访问外层函数的变量
- 将内存函数作为外层函数的返回,此内层函数就是闭包函数
2. 闭包的好处和缺点
- 优点:不定义全局变量,也可以让函数持续访问和修改一个外部变量
- 优点:闭包函数引用的外部变量,是外层函数的内部变量。作用域封闭难以被
误操作修改 - 缺点:额外的内存占用
3. nonlocal关键字的作用
- 在闭包函数(内部函数中)想要修改外部函数的变量值
- 需要用nonlocal声明这个外部变量
装饰器
学习目标:
- 掌握装饰器的作用和用法
装饰器其实也是一种闭包,其功能就是在不破坏目标函数原有代码的功能的前提下,为目标增加新功能
def sleep():
import random
import time
print("睡眠中")
time.sleep(random.randint(1, 5))
我们现在希望给sleep函数增加一个新功能:
- 在调用sleep前输出:我要睡觉了
- 在调用sleep后输出:我起床了
我们可以用这种写法实现:
print("我要睡觉了")
sleep()
print("我起床了")
但是这种写法未免有点捞了,而前面我们恰好又学了闭包,所以
装饰器的一般写法(闭包)
def sleep():
import random
import time
print("睡眠中")
time.sleep(random.randint(1, 5))
# 定义一个闭包函数,在闭包函数中执行目标函数,并完成功能的添加
def outer(func):
def inner():
print("我要睡觉了")
func()
print("我起床了")
return inner
fn = outer(sleep)
fn()
在上面这段代码中,outer外部函数接收sleep函数传参,然后定义内部inner函数,内部函数就执行目标函数并完成功能的添加,最后再返回inner,通过接受inner的返回值,再去调用inner内部的功能
从上面这个案例来看,定义一个闭包函数,在闭包函数内部:
- 执行目标函数
- 并完成功能的添加
装饰器的语法糖写法
在上面的写法中,我们需要先的到返回值,然后调用返回值
的函数,这样看起来是不是有点不太聪明的样子?
所以我们就可以通过@outer来简化这个流程
代码案例
# 定义一个闭包函数,在闭包函数中执行目标函数,并完成功能的添加
def outer(func):
def inner():
print("我要睡觉了")
func()
print("我起床了")
return inner
@outer
def sleep():
import random
import time
print("睡眠中")
time.sleep(random.randint(1, 5))
sleep()
注意:
- 装饰器接受了一个函数并返回一个新的函数,新函数的参数与被修饰的函数保持一致
- 框架必须在被装饰的函数上方
设计模式
学习目标:
- 掌握单例模式的作用和写法
- 掌握工厂模式的作用和写法
设计模式是一种编程套路,可以极大的方便程序的开发。
最常见、最经典的设计模式,就是我们所学习的面向对象了。
除了面向对象外,在编程中也有很多既定的套路可以方便开发,我们称之为设计模式:
- 单例、工厂模式
- 建造者、责任链、状态、备忘录、解释器、访问者、观察者、中介、模板、代理模式。
- 等等模式
设计模式非常多,我们主要挑选了2个经常用到的进行讲解
单例模式

单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在。
在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场。
定义: 保证一个类只有一个实例,并提供一个访问它的全局访问点
适用场景: 当一个类只能有一个实例,而客户可以从一个众所周知的访问点访问它时。

小结
1. 什么是设计模式
- 设计模式就是一种编程套路。
- 使用特定的套路得到特定的效果
2. 什么是单例设计模式
单例模式就是对一个类,只获取其唯一的类实例对象,持续复用它。
.节省内存
·节省创建对象的开销
工厂模式
当我们需要大量创建一个类的实例的时候,就可以使用工厂模式
即,从原生的使用类的构造区创建对象的形式迁移到基于工厂提供的方法去创建对象的形式

使用工厂类的get person()方法去创建具体的类对象优点:
- 大批量创建对象的时候有统一的入口,易于代码维护·当发生修改,仅修改工厂类的创建方法即可
- 符合现实世界的模式,即由工厂来制作产品(对象)
说人话就是,面对需要构建多个对象的时候,统一接口,需要修改某个对象类属性直接去改,改类的时候也不影响你调用接口构建对象
小结
1.什么是工厂模式
- 将对象的创建由使用原生类本身创建转换到由特定的工厂方法来创建
2.好处
- 大批量创建对象的时候有统一的入口,易于代码维护
- 当发生修改,仅修改工厂类的创建方法即可
- 符合现实世界的模式,即由工厂来制作产品(对象)
多线程
学习目标:
**1. 了解什么是进程、线程
- 了解什么是并行执行
- 掌握使用threading模块完成多线程编程**
进程、线程和并行执行
进程、线程
现代操作系统比如Mac OS X,UNIX,Linux,Windows等,都是支持“多任务”的操作系统。
进程: 就是一个程序,运行在系统之上,那么便称之这个程序为一个运行进程,并分配进程ID方便系统管理。
线程: 线程是归属于进程的,一个进程可以开启多个线程,执行不同的工作,是进程的实际工作最小单位。
进程就好比一家公司,是操作系统对程序进行运行管理的单位
线程就好比公司的员工,进程可以有多个线程(员工),是进程实际的工作者
操作系统中可以运行多个进程,即多任务运行
一个进程内可以运行多个线程,即多线程运行
注意点:
- 进程之间是内存隔离的,即不同的进程拥有各自的内存空间。这就类似于不同的公司拥有不同的办公场所。
- 线程之间是内存共享的,线程是属于进程的,一个进程内的多个线程之间是共享这个进程所拥有的内存空间的。这就好比,公司员工之间是共享公司的办公场所。

并行执行
并行执行的意思指的是同—时间做不同的工作。
进程之间就是并行执行的,操作系统可以同时运行好多程序,这些程序都是在并行执行。
除了进程外,线程其实也是可以并行执行的,也就是比如一个Python程序,其实是完全可以做到;
- 一个线程在输出:你好
- 一个线程在输出:Hello
像这样一个程序在同一时间做两件乃至多件不同的事情,我们就称之为:多线程并行执行
总结
1.什么是进程
- 程序在操作系统内运行,即成为一个运行进程
2.什么是线程
- 进程内部可以有多个线程,程序的运行本质上就是由进程内部的线程在实际工作的。
3.什么是并行执行
- 多个进程同时在运行,即不同的程序同时运行,称之为:多任务并行执行.一个进程内的多个线程同时在运行,称之为:多线程并行执行
多线程编程
threading模块
绝大多数编程语言,都允许多线程编程,python也不例外
python的多线程编程可以通过threading模块实现
语法规则:
import threaaing
thread_obj = threading.Thread([group [, target [, name [, args [,kwargs]]]]])
其中:
- group:暂时无用,未来功能的预留参数
- target:执行的目标任务名
- args:以元组的方式给执行任务传参
- kwargs:以字典方式给执行任务传参
- name:线程名,一般不用设置
多线程编程
直接上代码案例吧
代码案例
import time
import threading
def sing():
while True:
print("第一次鸦片战争的我,你该怎么去否认")
time.sleep(2)
def dance():
while True:
print("基尼太美")
time.sleep(2)
# 创建跳舞的线程
dance_thread = threading.Thread(target=sing)
sing_thread = threading.Thread(target=dance)
# 开始两个线程
dance_thread.start()
sing_thread.start()
上面这个案例就能展现多线程的效果,但是,咱们来看看下面这个案例可以实现同样的效果吗?
import time
import threading
# 多线程编程
# 创建执行方案
class Sing_Dance:
def sing(self):
while True:
print("第一次鸦片战争的我,你该怎么去否认")
time.sleep(2)
def dance(self):
while True:
print("基尼太美")
time.sleep(2)
# 创建唱歌的执行方法
def sing_use(sing_dance: Sing_Dance):
sing_dance.sing()
# 创建跳舞的执行方法
def dance_use(sing_dance: Sing_Dance):
sing_dance.dance()
# 创建对象
op = Sing_Dance()
# 创建线程
# 创建唱歌线程
sing_thread = threading.Thread(target=sing_use(op,))
# 创建跳舞的线程
dance_thread = threading.Thread(target=dance_use(op,))
# 开始两个线程
sing_thread.start()
dance_thread.start()
通过运行,我们发现是可以运行的。但是,遗憾的是变成了单线程,那该如何解决这个问题呢?
我们需要传参的话,有两种方式:
- args参数通过元组(按参数顺序)的方式传参
- 使用kwargs参数用字典的形式传参
所以我们只需要对上面代码稍作修改,改成下面这样就可以实现双线程:
# 创建唱歌线程
sing_thread = threading.Thread(target=sing_use, args=(op,))
# 创建跳舞的线程
dance_thread = threading.Thread(target=dance_use, args=(op,))
再来看一个args和kargs传参的代码案例
代码案例
import time
import threading
def sing(msg):
while True:
print(msg)
time.sleep(2)
def dance(msg):
while True:
print(msg)
time.sleep(2)
# 通过args元组传参
dance_thread = threading.Thread(target=sing, args=("第一次鸦片战争的我,你该怎么去否认", ))
# 通过kwargs字典传参
sing_thread = threading.Thread(target=dance, kwargs={"msg": "基尼太美"})
# 开始两个线程
dance_thread.start()
sing_thread.start()
网络编程
学习目标:
**1. 了解什么是Socket网络编程
- 基于Socket完成服务端程序开发
- 基于Socket完成客户端程序开发**
服务端开发
Socket和Socket服务端编程
Socket介绍

客户端和服务端
2个进程之间通过Socket进行相互通讯,就必须有服务端和客户端
Socket服务端: 等待其它进程的连接、可接受发来的消息、可以回复消息
Socket客户端: 主动连接服务端、可以发送消息、可以接收回复

Socket服务端编程
主要分为如下几个步骤:
创建socket对象
import socket socket_server = socket.socket()绑定socket_server到指定IP和地址
socket_server.bind(host,port)服务端开始监听端口
socker _server.listen(back1og) # backlog为int整数,表示允许的连接数量,超出的会等待,可以不填,不填会自动设置一个合理值接收客户端连接,获得连接对象
conn.address = socket_server.accept() print(f""接收到客户端连接,连接来自: {address}") # accept方法是阻塞方法,如果没有连接,会卡再当前这一行不向下执行代码 # accept返回的是一个二元元组,可以使用上述形式,用两个变量接收二元元组的2个元素客户端连接后,通过recv方法,接受客户端发送的消息
# 可以通过while True无限循环来持续和客户端进行交互
# 可以通过判定客户端发来的持续标记,如exit来退出无限循环
while True:
cv(1024).decode("UFT-8")
# 通过recv方法得到的返回值是字节数组(bytes),可以通过decode使用“UTF-8”解码为字符串
# recv方法的传参是buffsize,缓冲区大小,一般设置为1024即可
if data == "exit":
break
print("接受到发送来的数据", data)
- 通过conn(客户端当次连接对象),调用send方法可以回复消息
while True:
data = conn.recv(1024).decode("UTF-8")
if data == "exit":
break
print("接受到发送来的数据", data)
conn.send("反馈一下收到了数据", encode("UTF-8"))
- conn(客户端当次连接对象)和socket_server对象调用close方法,关闭连接
代码案例
# 导入包
import socket
# 创建Socket对象
socket_server = socket.socket()
# 绑定ip地址和端口
socket_server.bind(("localhost", 8888))
# 监听端口————listen方法内接受一个整数传参值,表示接受的链接数量
socket_server.listen()
# 等待客户端连接—————accept返回的是二元元祖(链接对象, 客户端信息)
'''
conn = socket_server.accept()[0] # 客户端和服务器的链接对象
adress = socket_server.accept()[1] # 客户端的地址信息
'''
# 或者可以这么写
# accpet方法是阻塞方法,如果没有客户端链接就会止步于这一行,不向下执行
conn, address = socket_server.accept()
print(f"接收到了客户端的链接,客户端的信息是:{address}")
while True:
# 接受客户端信息————使用客户端和服务端的本次连接对象,而不是server_socket对象
# recv方法接受的参数是缓冲区大小,一般给1024字节即可
# recv方法的返回值是一个字节数组,也就是bytes对象,不是字符串。可以通过decode方法进行UTF-8编码,将字节数转换为字符串对象
data: str = conn.recv(1024).decode("UTF-8")
print(f"客户端发来的消息是:{data}")
# 发送回复消息
# 回复消息需要我们传bytes字节,但是我们传入的数据类型是str,所以上面可以bytes转str,那么同样也能通过encode这个方法转回去
# encode可以将字符串编码转换为字节数组对象
msg = input("请输入你要和客户端回复的消息:") # 接受消息
if msg == "exit":
# 关闭链接
conn.close()
socket_server.close()
exit()
else:
conn.send(msg.encode("UTF-8"))
客户端开发
主要分为如下几个步骤:
创建Socket对象
import socket socket_server = socket.socket()链接到服务端
# 2. 连接到服务器————客户端就会一直使用这个变量socket_client,不会再得到额外的对象(服务端会再得到一个地址)
socket_client.connect(("localhost", 8888))
- 发送消息——通过while实现无限循环
while True:
send_msg = input("请输入要发送的消息:")
if send_msg == "exit":
# 通过特殊标记关闭链接,退出程序
exit()
else:
# 消息需要编码为字节数组
socket_client.send(send_msg.encode("UTF-8"))
- 接受返回消息
while True: send_msg = input("请输入要发送的消息:").encode("UTF-8") socket_client.send(send_msg) # 1024是缓冲区大小,一般1024即可 # recv方法是阻塞式的,即不接收到返回,就卡在哪里等待 recv_data = socket_client.recv(1024) # 接收下消息需要通过UTF-8解码为字符串 print("服务端回复消息为:", recv_data.encode("UTF-8"))
- 关闭链接
socket_client.close()
OK,接下来让我们来实战一下客户端和服务端的链接吧
代码案例
# 客户端的搭建
# 创建socket对象
import socket
socket_client = socket.socket()
# 连接到服务器
socket_client.connect(("localhost", 8888))
# 发送消息
while True:
send_msg = input("客户端发送的消息:")
if send_msg == "exit":
# 关闭链接,退出程序
socket_client.close()
exit()
else:
# 发送消息,encode是将字符串UTF-8转化为字符集发送给客服端
socket_client.send(send_msg.encode('UTF-8'))
# 接受消息,1024是缓冲区大小,decode是将字符集解码为UTF-8(字符串)
recv_data = socket_client.recv(1024)
print(f"客服端回复的消息是:{recv_data.decode('UTF-8')}")
客户端有了,服务端也搭建完毕,接下来就是互动咯
- 首先下运行客服端,毕竟没服务哪里来的客户对吧?
- 接下来运行客户端链接到服务端来
- 接下来就可以在两个端口做出下面这样的互动啦

正则表达式
基础匹配
学习目标:
**1. 了解什么是正则表达式
- 掌握re模块的基础使用**
正则表达式
正则表达式,又称规则表达式(Regular Expression),是使用单个字符串来描述、匹配某个句法规则的字符串,常被用来检索、替换那些符合某个模式(规则)的文本。
简单来说,正则表达式就是使用:字符串定义规则,并通过规则去验证字符串是否匹配。
比如,验证一个字符串是否是符合条件的电子邮箱地址,只需要配置好正则规则,即可匹配任意邮箱。比如通过正则规则:(^[w-]+(\.[w-]+)*@[\w-]+(\.[\w-]+)+$)即可匹配一个字符串是否是标准邮箱格式
但如果不使用正则,使用if else来对字符串做判断就非常困难了。
正则的三个基础方法
- Python正则表达式,使用re模块,并基于re模块中三个基础方法来做正则匹配。
- 分别是: match、search、findall三个基础方法
re.match(匹配规则,被匹配字符串)
从被匹配字符串开头进行匹配,匹配成功返回匹配对象(包含匹配的信息),匹配不成功返回空,如:
```python从被匹配字符串开头进行匹配,匹配成功返回匹配对象(包含匹配的信息),匹配不成功返回空
import re
s = ‘python itheima python itheima python itheima ‘
print(s)
result = re.match(‘python’, s)
print(result) #
print(result.span()) # (0,6)
print(result.group()) # python
s = ‘1python itheima python itheima python itheima’
result = re.match(‘ python’, s)
print(result) # None
**search(匹配规则, 被匹配的字符串)**
>搜索整个字符串,找出匹配的。从前往后,找到第一个后就停止,不会继续向后,整个字符串都找不到,返回None,如:
```python
# 搜索整个字符串,找出匹配的。从前往后,找到第一个后就停止,不会继续向后
import re
s = '1python666itheima666python666'
result = re.search('python', s)
print(result) # <re.Match object; span=(1,7), match= ' python ' >
print(result.span()) # (1,7)
print(result.group()) # python
# 整个字符串都找不到,返回None
s = 'itheima666'
result = re.search('python', s)
print(result) # None
findall(匹配规则, 被匹配的字符串)
匹配整个字符串,找出全部匹配项,找不到就返回空list:[],如:
import re
# 匹配整个字符串,找出全部匹配项
s = '1python666itheima666python666'
result = re.findall('python', s)
print(result) # ['python', 'python']
# 找不到就返回空list:[]
s = '1python666itheima666python666'
result = re.findall('itcast', s)
print(result) # []
总结
1. 什么是正则表达式
- 是—种字符串验证的规则,通过特殊的字符串组合来确立规则用规则去匹配字符串是否满足
已保存到这台电脑 - 如
(^[w-]+(\.[w-]+)*@[\w-]+(\.[\w-]+)+$)可以表示为一个标准邮箱的格式
2. re模块的三个主要方法
- re.match,从头开始匹配,匹配第一个命中项
- re.search,全局匹配,匹配第一个命中项
- re.findall,全局匹配,匹配全部命中项
元字符匹配
关于这模块,我的建议是直接用AI生成或者在网上找现成的,没必要花大功夫去记忆这些规则
学习目标:
**1. 掌握正则表达式的各类元字符规则
- 了解字符串的r标记的作用**
在刚才我们只是进行了基础的字符串匹配,而正则最强大的功能在于元字符匹配规则
单字符匹配

数量匹配

边界匹配

分组匹配

搜索
最新文章
- 1. 这是一个测试
- 2. 502 Bad Gateway nginx.md
- 3. centos7.9系统更新python3至最新
- 4. Linux学习笔记
- 5. 重启uwsgi时遇见的问题